
This post documents the outcomes of a new feature of Calibre available in version 1.0: docx conversion. The docx file is firstly converted to HTMLZ in order to be converted again to MarkDown through Pandoc. An automated version of the process (bash script) is available at the bottom.
We are going to use a test document provided by Calibre team, downloadable here. The document has the following features:

Test Document in .docx, shown in LibreOffice
- Inline formatting
- Fonts
- Paragraph level formatting
- Tables
- Footnotes & Endnotes
- Dropcaps
- Links
- Table of Contents
- Images
- Lists
First, we convert the .docx to HTMLZ using Calibre. To do so add the test document to Calibre and right-click to convert it individually.
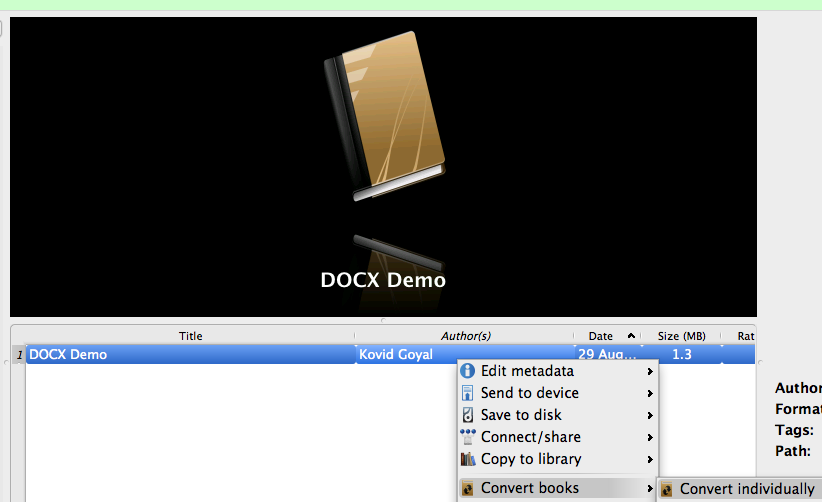
Choose HTMLZ as output format click OK. You will then find your .htmlz in the containing folder of your document (right-click on the element > Open containing folder).
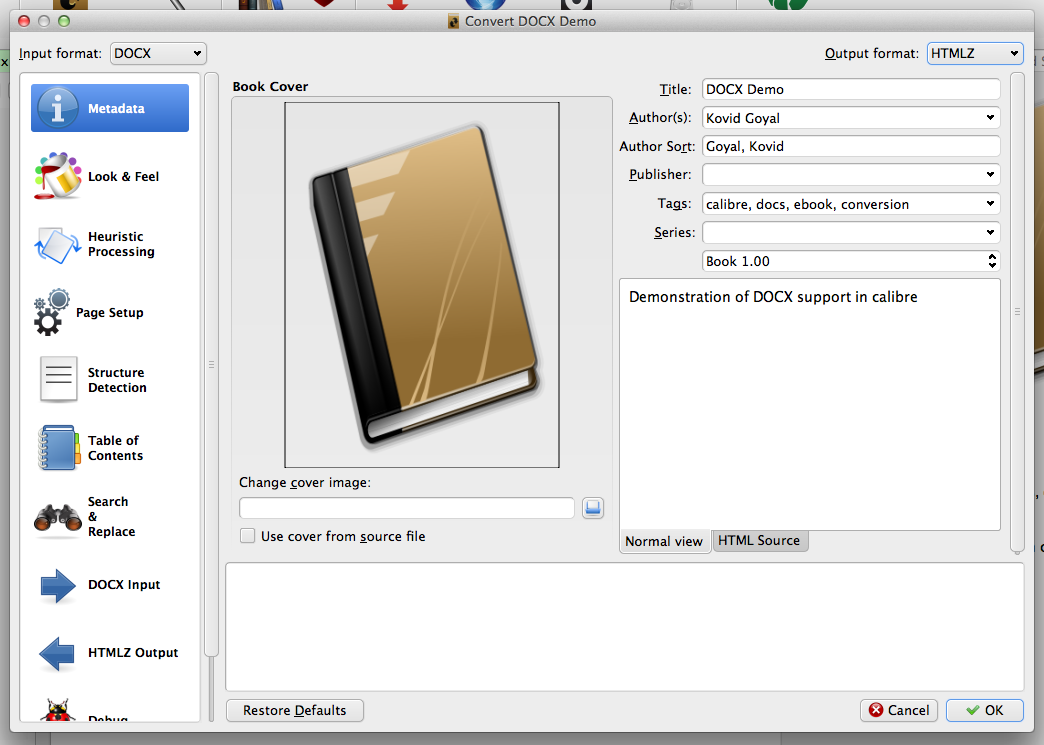
The HTMLZ is a zip file containing an HTML file along with images, style, etc. Therefore in order to access those files simply change the extensions from .htmlz to .zip and uncompress.
The result of the conversion is pretty decent: except for “Paragraph level formatting”, everything else is preserved, especially footnotes (that were the most labour intensive issue in the previous processes and still not solved).
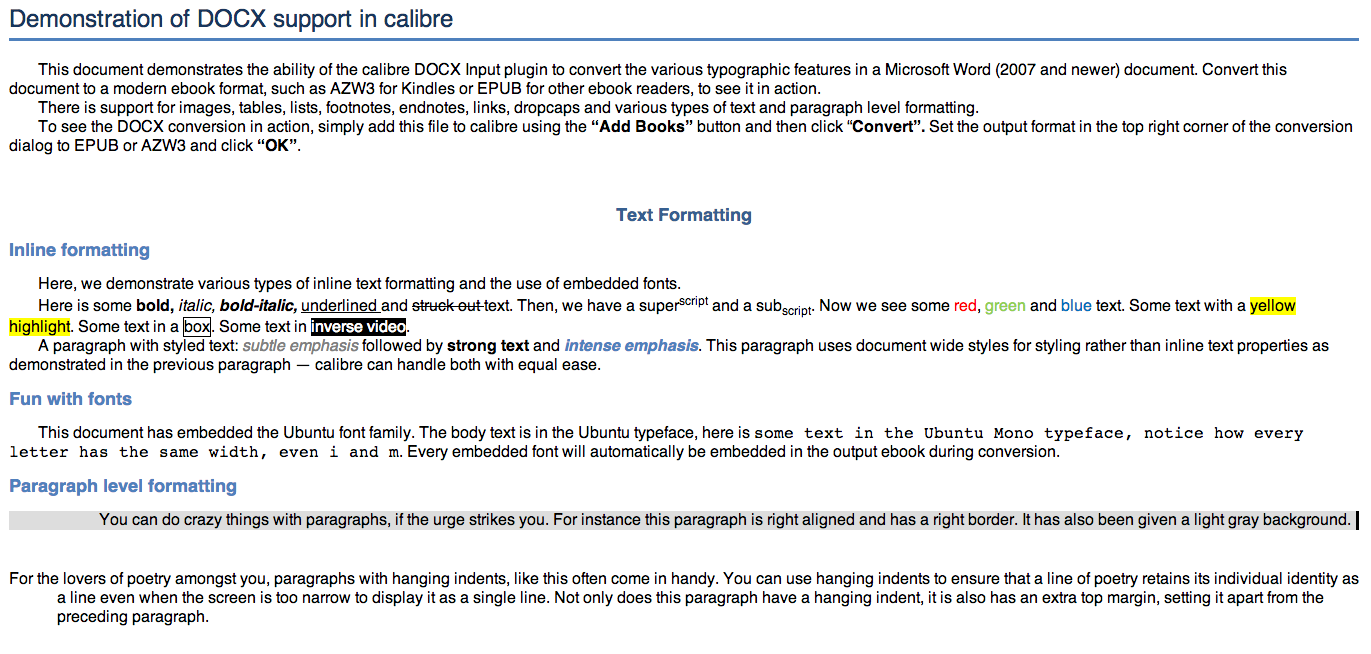
The HTML document
Let’s now use Pandoc to convert the .html to MarkDown.
pandoc -f html -t markdown -o output.html your_forlder/index.html
Here you can download the output MarkDown file.
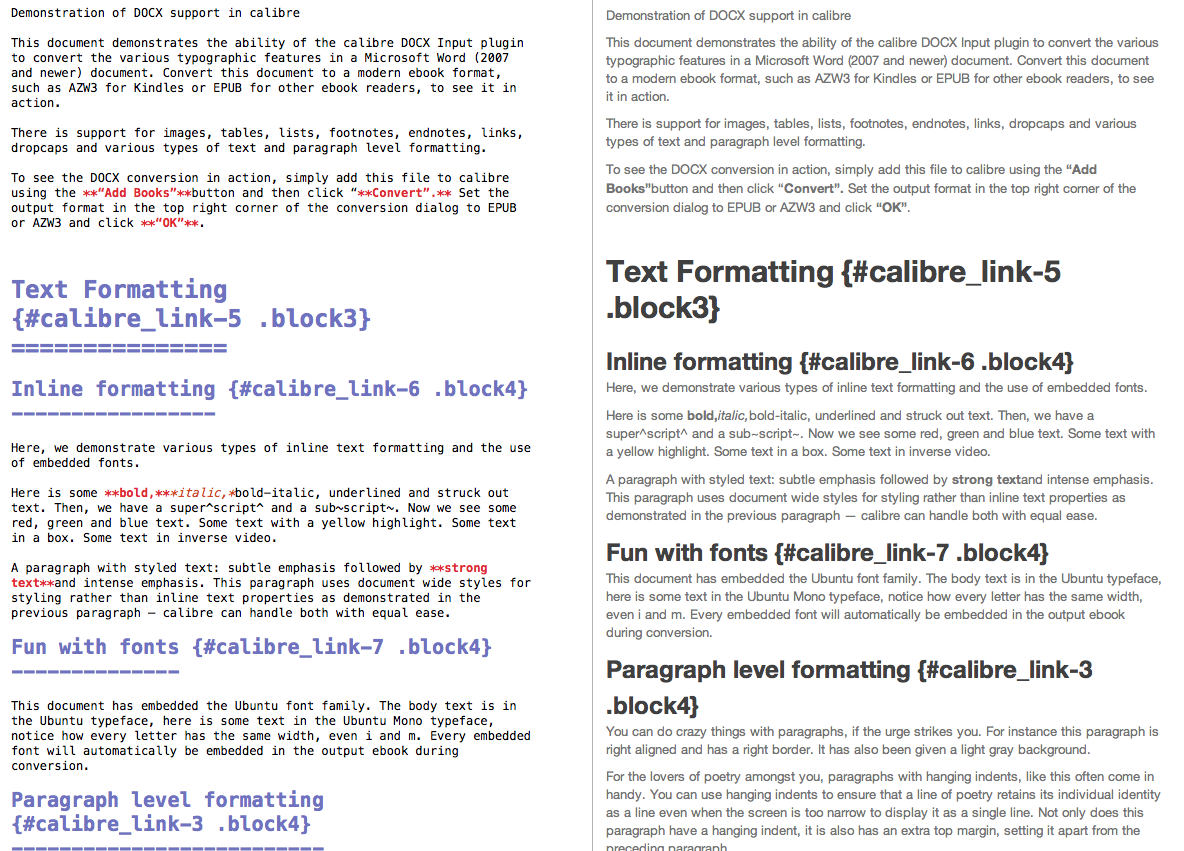
The MarkDown output as shown in Mou
Let’s now go through the features.
Inline formatting
- Bold and italic are preserved, even though there are problems when they are one next to each other;
- Underlined, struck out, superscript, subscript, colors, highlight are not preserved.
Fonts
Fonts are not preserved.
Paragraph level formatting
Paragraph level formatting is not preserved.
Tables
Tables are not preserved.
Footnotes & Endnotes
Footnotes and endnotes are preserved as links, even though the syntax is not correct. This in any case would be solved quickly with a find & replace or regular expression.
Dropcaps
Dropcaps are not preserved.
Links
Links are preserved.
Table of Contents
Table of Contents are preserved as sets of links.
Images
Images are preserved.
Lists
Both ordered and unordered lists are preserved.
Multi-level lists and continued lists have problems.
Automated version of the process (bash script)
In order to use the automated version you need:
- Calibre’s Command Line Interface activated: On OS X you have to go to Preferences->Advanced->Miscellaneous and click install command line tools to make the command line tools available. On other platforms, just start a terminal and type the command.
- An unzip tool: on OS X I use “unzip”.
#!/bin/bash
mkdir temp
cp $1 temp
cd temp
ebook-convert $1 output.htmlz
unzip output.htmlz
cd ..
pandoc -f html -t markdown -o output.md temp/index.html
rm -R temp