Authorized transcript of Bruce Sterling’s lecture during the TU Eindhoven conference AI for All, From the Dark Side to the Light, November 25, 2022, at Evoluon, Eindhoven, co-organized by Next Nature. Website of the event: https://www.tue.nl/en/our-university/calendar-and-events/25-11-2022-ai-for-all-from-the-dark-side-to-the-light. YouTube link of the talk: https://www.youtube.com/watch?v=UB461avEKnQ&t=3325s
—
It’s nice to be back in Eindhoven, a literal city of light in a technological world. I am here to discuss one of my favourite topics: artificial intelligence. The Difference Engine is a book that my colleague William Gibson and I wrote 33 years ago. The narrator of this book happens to be an artificial intelligence because we were cyberpunks at the time.

At the time we were talking to people in the press and they said: you science fiction writers like to write about computers, what if a computer started writing your novels? This was supposed to be some kind of existential threat to us. But we really liked computers. We had no fear of them, so we thought, oh, that might be amusing… why don’t we imitate a computer writing a novel? And this is the result. The book is still in print.

Here is the source of the problem: the infamous 1956 Dartmouth conference where ambitious computer scientists from the first decade of the computer science field gathered. They decided that since they were working on thinking machines, they should take this idea seriously and try to invent some machines and systems that could actually think. And they’re going to take computer science, they’re going to launch an imperialistic war on metaphysics, philosophy and psychology and establish whether software really is thought. And whether thought can be abstracted and whether there are rules for talking about intelligence. At the time they wrote some nice manifestos about it. I read them, even though I was only two years old when the event happened. Our novel is halfway between this old-school artificial intelligence and today’s AI. As a long-term fan of this rather tragic branch of computer science, 2022 has been the wildest year that artificial intelligence ever had. This is the first time there’s been a genuine popular craze about it. I’m going to spend the rest of my 45 minutes and 48 slides trying to tell you what the hell I think is going on.

This is artificial intelligence, the business side of it. If you lump in everything that could be plausibly called artificial intelligence, the old-school rules-based software code, and then the statement style of artificial intelligence, this is all of it and it’s pretty big. And it has never taken over anything completely. It’s just there are areas where it applies to various sectors airspace, finance, pipeline stuff, and data access. It’s very big. It’ s a mind map from Firstmark venture capital. Matt Turk photographed it. You’re going to be neck-deep in this. I’m not going to talk about all that. I’m going to get around to talking, to text, to image generators. But this is a generative AI, not even old-school artificial intelligence, not even necessarily machine learning and deep learning.
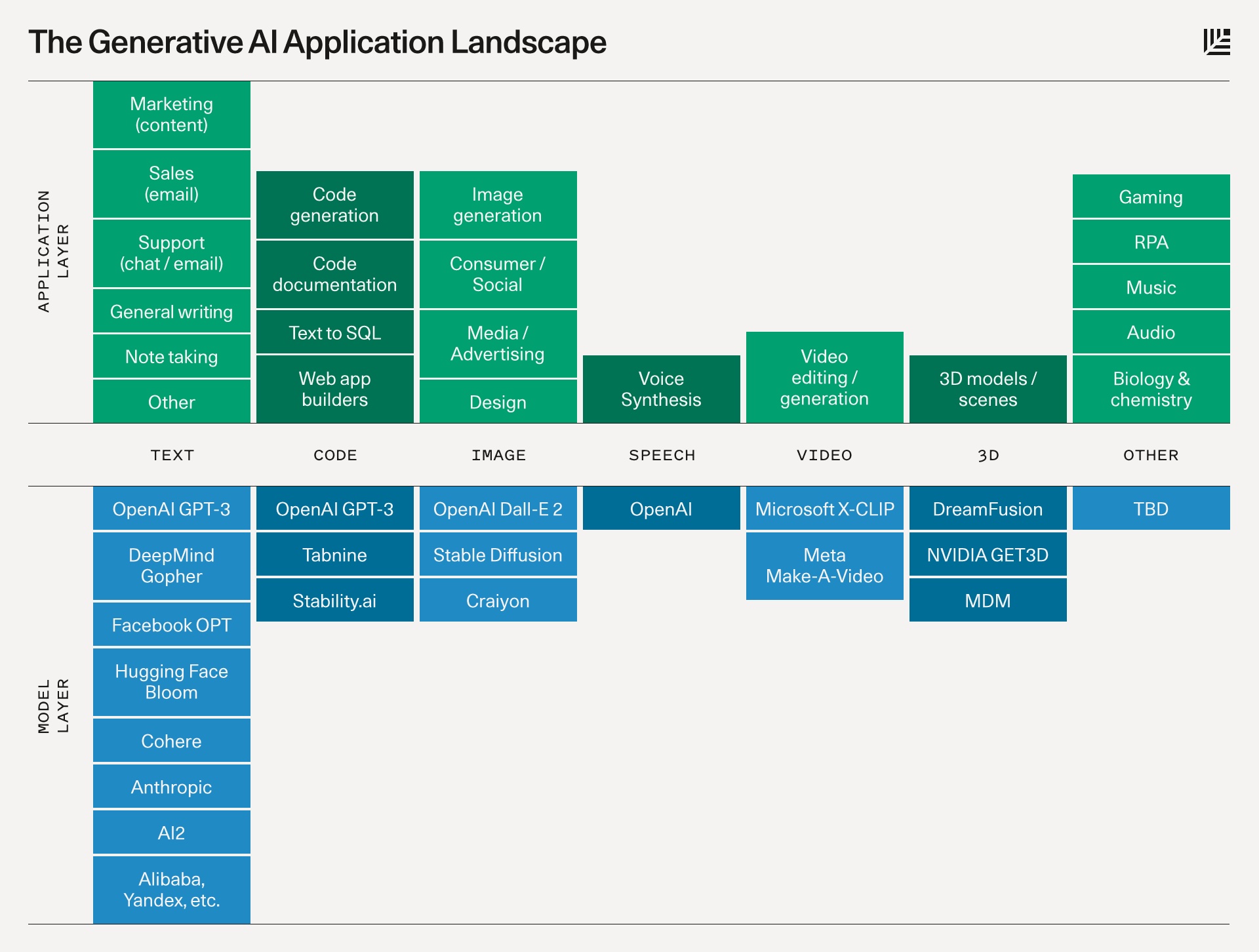
I am here to talk about text-to-image generators. This is actually generative AI, which is what went wild this year. It is a generative application landscape. This is a subset of AI, not even machine learning, but this is where all the heat and light are coming from. Right now. People are just going nuts about it.

And these are some of the technical platforms that support it. AI Machine learning, deep learning. You can see this. Just look these guys up. I could spend all day gossiping about them. Some are up, and some are down. Haul out your phones. Take pictures of this. Go take your pinky fingers. Look them up on the Internet. That’s a heck of a lot going on here.

And then, these are the visual guys. These are actual text-to-image generation outfits here. Platforms, companies, start-ups, most of them young, some of them younger than this February. But just like a small army of these guys, some of them younger than February 2022, coming out of the lab and schools, in the garages, dropping out of companies, scaring up venture capital. It’s a wild scene.
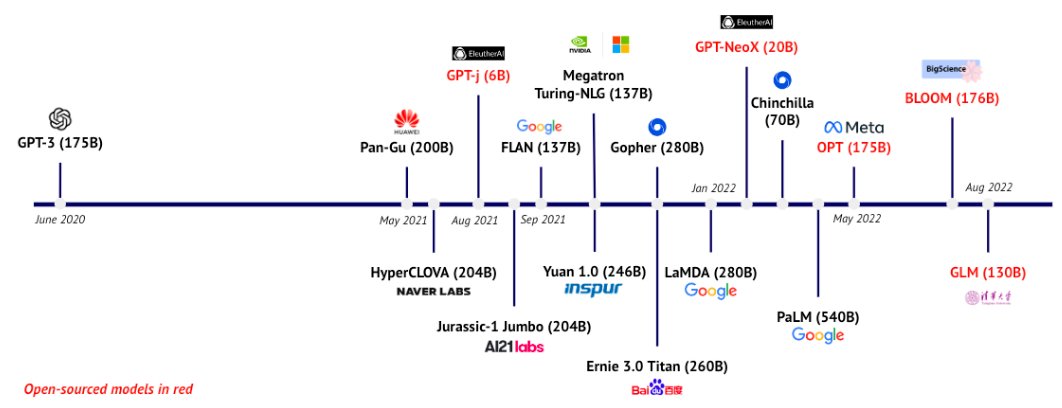
Here are the platforms that are supporting them at the moment. Practically none of these companies are making any money. What they’re busy doing is trying to muscle up, beef up the platforms and try to find some applications for these breakthroughs that they’re having. And the platforms that are in red are the open-source platforms. And these are the closest thing to AI for all that anybody has ever had. You can fire these up. You can look at them on the Web. You can download them from GitHub. Computer science breakthroughs are never going to be for all people. As you can see they started back in 2021 and picked up steam in a major fashion.

These are some of the little businesses. These are startups. Nine out of ten of these guys are going to die. This is not the future. This is not an overpowering way. These are all startups. Even the ones that survive are going probably going to get acquired. Look on the Internet, chase them down, follow them on social media, and read their white papers.
So what are they doing?
I’m going to talk about artwork because I have a problem here. I happen to be the art director of a technology art festival in Turin, Italy, which is where I flew from to be with you today. And we know that we’re going to be getting a lot of AI art, so we may as well do an event on AI art. We’ve got to figure out sort of what’s good and what we want to show the public of Turin. I’ve got to make aesthetic and cultural decisions about what matters. There are hundreds of thousands of users who’ve appeared in a matter of mere months, and they’ve generated literally millions of images. There’s a quarter of 1 million or 250 million images on these services. You just tell them what to do and offer them a prompt. They generate stuff very quickly.

This image happens to be Amsterdam-centric, I am messing with the Amsterdam imagery there.

You can do very elaborate kind of swirly arabesque stuff.

You could do fantastic unearthly landscapes that look like black and white photography.

You can mess about with architecture or do strange 3D geometric stuff.

You could do pretty girls. Those are always guaranteed to sell. There are megatons of pretty girls that have been generated, probably more pretty girls in the past year than in the entire history of Pretty Girl art today because you could just do it. Literally, press a button and have a hundred pretty girls.

Fantasy landscapes, odd-looking 3D gamer set stuff. You can just put in the word utopia and it will build you utopias. Not two will be the same.

The utopia prompt. One could do utopias, all day, all night. Do you like green ones? No, you like the blue ones. You know, it’s happy. You don’t have to say bad utopia. Good utopia. There is just an endless supply. Basically infinite. I mean, it’s not infinite because all these images are JPEGs. No, not really. Paintings are not really photographs. They’re conjugations of JPEGs. So what you’re seeing is like 256 by 256 of JPEGs. And, you know, statistically, there’s only so many ways you could vary the colour in a grid of 256 by 256. But these systems know how to do that.

This is a Refik Anadol, who’s from Istanbul and is working out of LA. He’s the world’s only truly famous artificial intelligence artist. He has been touring the world for the past 4 or 5 years doing these epically large motion graphics, mostly on buildings, using databases of people who are hiring him. Take out everything in your files, turn it into an artificial intelligence landscape and broadcast on your building, generating a lot of traffic. If you happen to be a museum director and Refik Anadol shows up with one of his projected shows, you’d better have the museum store ready to go because they’re going to be lined up around the block for Refik. He will give you all the artificial intelligence that you can eat, on time, and under budget. And the public loves it flat out.
Let’s explain how all this works technically. What does a text do when it generates, if you try to take a picture of it? This would be a selfie.

What you see here is a Google tensor chip. It happens to be version three, which is already obsolete. They’re threatening to roll out number four. It’s going to be like Moore’s Law but then heavier. If you’re Google DeepMind and you’re doing Alphazero and you’re going to beat every other chess player in the world, you’re just going to wipe the floor with all the old-school chess-playing computers. You need these babies. About 5000 of these. Slot them up, and train them on chess. Don’t tell them. Tell them nothing except the rules. I’ll just invent chess and they’ll beat every other chess machine ever invented. You need 5000 of these racked up. It’s not going to come cheap. It will take a lot of voltage. What I don’t have here are nice, homely literary metaphors like ‘cyberspace’.
It’s like you got all these wires and all these protocols and all these messages flying around at random from node to node you can understand the routing systems and like the naming system and so forth. Or you can just say cyberspace. It is a metaphor because there really is no cyberspace. All there is are wires, storage units, built on top of web browsers–colossal stacks of interacting.
The police and the military really like AI, that’s not going away. It was a successful coinage. So, what’s a generator? How does it generate? All this happens to be a stable diffusion, one of the better-known generators among many other similar generators. They’re not all built the same. There are different architectures. You don’t just have one machine. You’ve actually got several different ones. Artificial intelligence is about deep learning, neural networks of connected computers on chips, each one of them separate. They don’t trade information with one another. You’ve got on one end the one that interprets the text. It just looks. At typed text. It doesn’t read books. It just literally reads alphanumeric characters, ASCII, and it breaks them up into powder. It doesn’t even look at the words, but it looks like the phonemes and the statistical probabilities of them affecting other phonemes. And this has been typical of AI-style machine translation for a while, but now they’ve gotten really quite good at it. So it’s kind of looking at whatever command it’s given and breaking that up into a kind of probabilistic dust, just like points in a vector space. But something like flour, if you think of it as like a sifting machine, you’re putting in the white flour and it’s got rocks and some other unnecessary things. Then you sieve back and forth. Put the words in and break the words up into little pieces of probability.
It then passes them to an image generator. In the next stage, it tries to come up with a rough consensus of what it might be in a postage stamp style. This is a little beginning, a hint as to what this image might become. After having sifted that one around until it’s got a rough kind of consensus. It passes that to a second part of the server, which doesn’t concern itself with words. It just takes the earlier image and it tries to focus the image, tighten it, brighten it and make it broader. And then that passes its own version of the image to yet another one, which is bigger and kind of more focused on prettification that expands the image onto a bigger scale and fits it into a particular format, polishes it up, makes it look like a camera photo and makes it look like a painting or a blueprint. The three of them don’t intercommunicate, they’re three separate sieves. And then the last one there is the auto encoder-decoder, which functions as an editor-publisher, and it looks at what’s come through this.
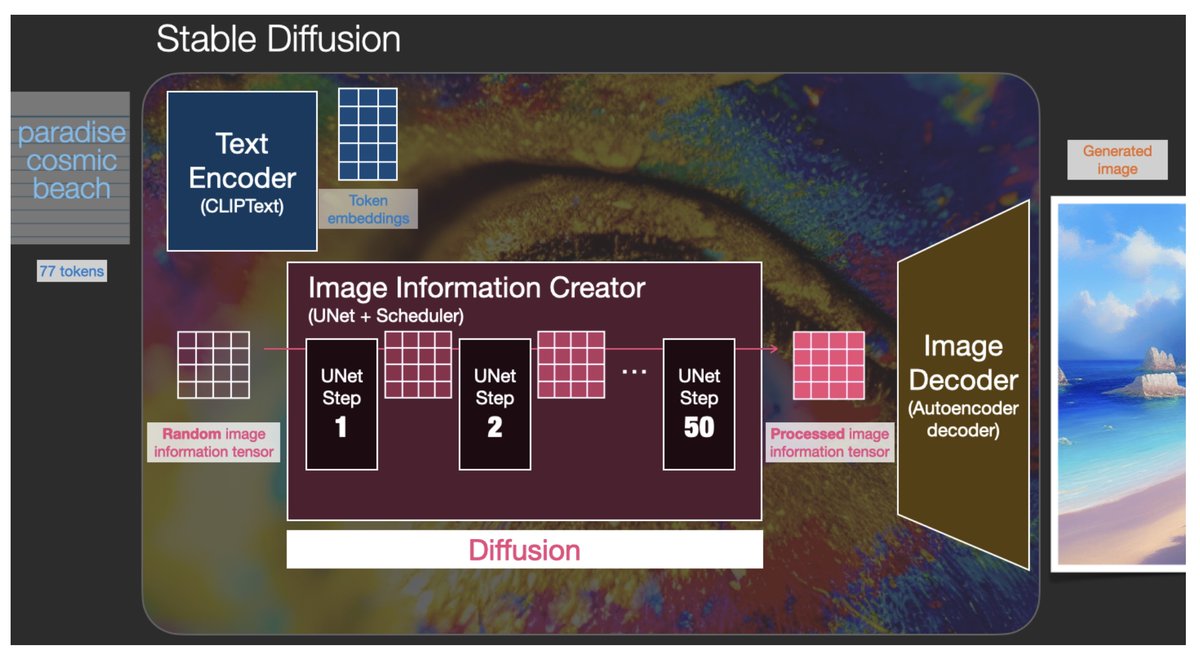
Pretty refined. But most of is rubbish, nonsense. It’s like throwing things out the window like an impatient editor or getting rid of bad paintings, like an angry gallerist, statistically comparing images to a database it has of successful paintings: this one’s obviously chaos, that one might pass. And then when it’ll select a few out of a great many which have been generated. It’ll actually edit it down to just a few and sort of print them or at least turn them into actual JPEGs and present them to the viewer on the website. It is astonishingly complicated, amazing that such a whopper-jawed thing works at all. And where it came from is not text-to-image generators, but image-to-text recognition. What happened here?
Several years ago Facebook and Google tried using computers to identify what was in photographs and JPEGs. They were looking for your face or tried to identify consumer items, basic surveillance capitalism procedures. And then one of the engineers said, okay, we can look at a photograph in our machine, will name what’s in it. What happens if we just give it the name and ask it to produce the photograph, literally turning the box upside down? What they got was deep dreaming, a hallucinatory mess. It just didn’t make any sense. But then they’ve worked on it and refined it to some extent. But this is really a crude and whopper-jawed thing here. I mean, it’s literally as if I’d like turned a recycling machine on its ear and I could put in broken glass and get out Greek vases. And nobody expected this. I don’t know anybody in computer science that ever predicted the existence of a text-to-image generator. It’s just one of those bizarre lines of technical development where you do.
Something as simple as turning it upside down and an entire industry hops out of Pandora’s box there. It’s really, really a funny and wild thing. So what’s wrong with it? I’m going to go into this now. It’s like not what’s wrong with it. More to be fairer to this technology, What are its innate characteristics? I mean, what is the grain of the material there? What is it good at doing and what is it not bad at doing? And if you were an art director or a museum curator, how would you judge what was like a good output and like just the stuff that’s like every day and there’s 250 millions of them and somebody’s got to do this work, and I’m trying to help here. This is the basic problem with all forms of generative AI: they’re not normal. They’re not they don’t they don’t fulfil the aspirations of the founders of AI. They have no common sense.

Here is the ‘healthy boy eating broken glass for breakfast’ result. He looks like a really happy kid. Ask an artist to draw a child gleefully eating broken glass, that’s a horror image. But since this machine lacks any common sense understanding, it doesn’t know what glass is. It doesn’t know what a boy is, doesn’t know what breakfast is. It’s the very opposite of an Isaac Asimov robot. No idea about possible harm. If you look at this, where’s the ethics? But then, it’s just some sieves that are turning text into image. It’s a Rube Goldberg machine to turn a huge database of any possible character connected to every JPEG pixel on the Internet. It’s just it’s a balancing act between all the text on the Internet and all the images on the Internet, the common crawl. If you look for the AI intelligence in there, it’s like, where.
Are the rules? Where are the decisions? Where’s the common sense? There’s not a trace of them, not one trace. It’s just a series of photos, produced by sophisticated filters, connected by equations, they’re not even wired together. It’s fantastic what they can figure out. They have zero common sense. That’s not even in the textbook. They don’t care. They don’t compete with anything. They don’t have to. These AIs don’t have ears. They don’t have photographs. They don’t have paintings. They have a statistical relationship between text and clumps of JPEG pixels.

I heard early on from users who were trying to put their prompts into these machines that they weren’t very good at hands.

It’s like, why are they not good at hands?
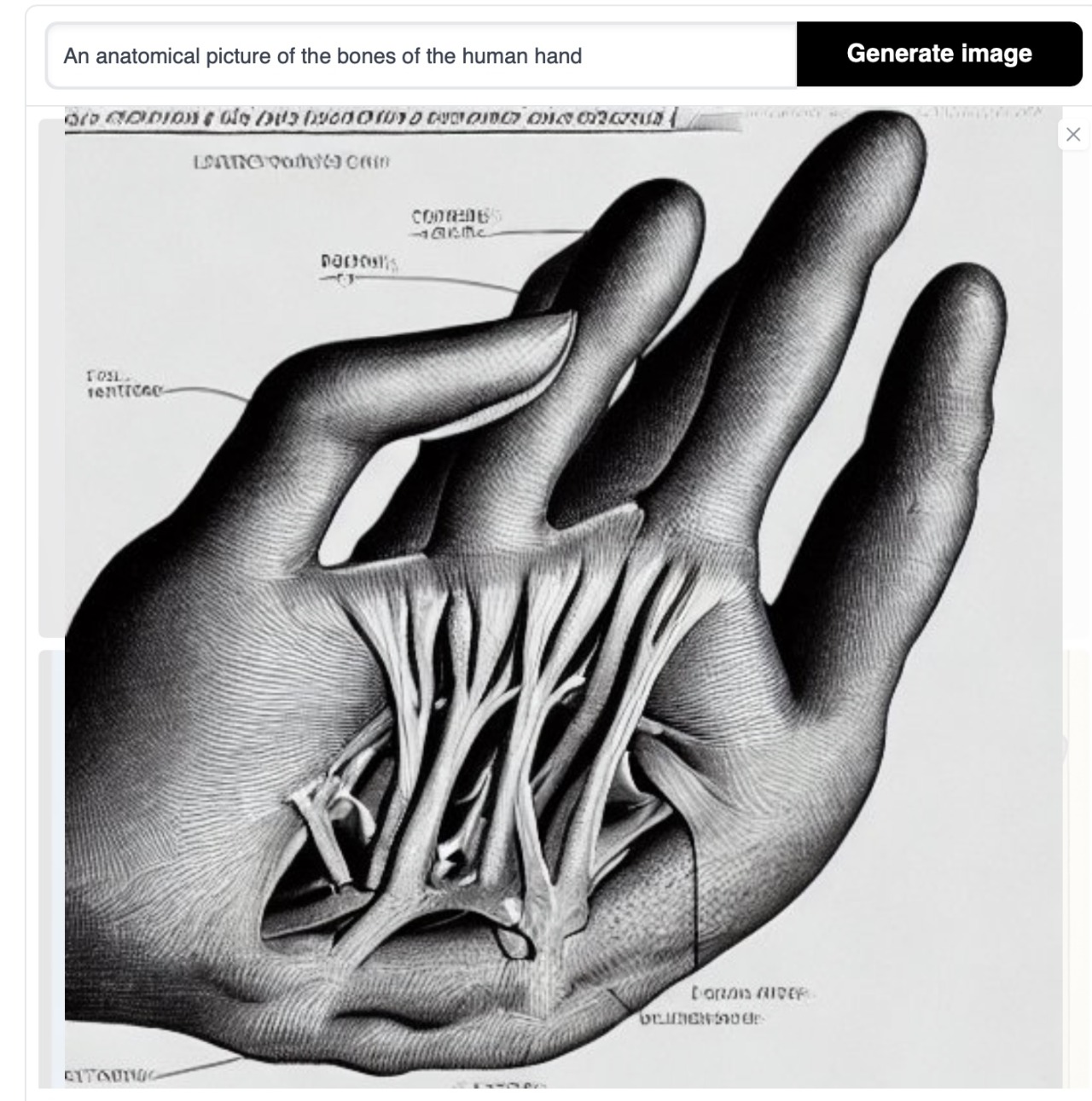
You know, a hand is one of the most common things on the Internet, there are millions and millions of pictures of them.

It just doesn’t understand the geometry and doesn’t know what three dimensions look like. It knows what a picture of a hand looks like.

This is a prompt in the Dutch language. It doesn’t know what a hand looks like in three dimensions. It doesn’t have a hand. It has no skin.

Count to five. It can’t count to five. Why? It does not draw. It does not photograph. It only generates.

How about the oldest hands ever drawn? Can’t do it.
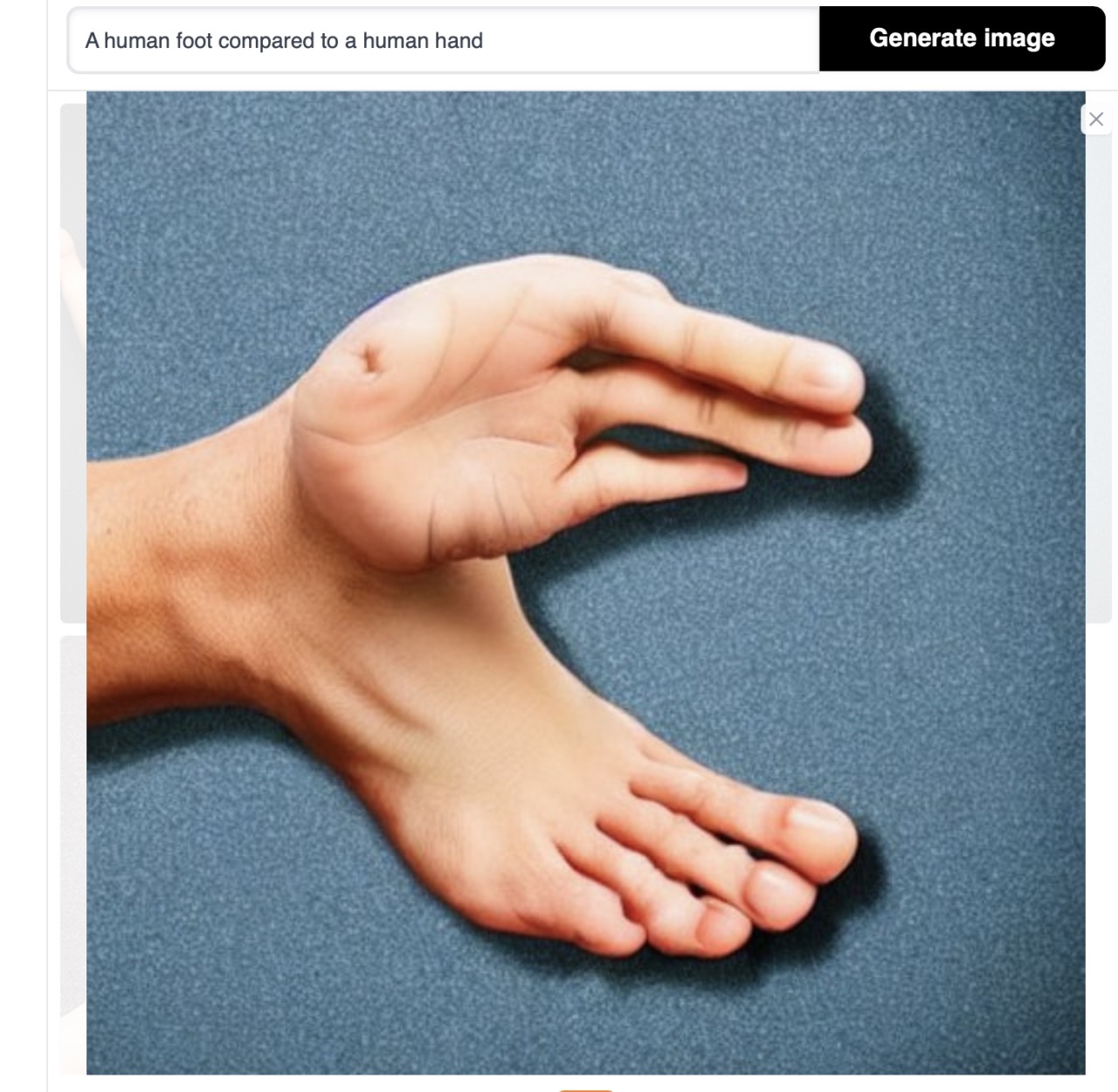
How about a foot? Can you compare a foot with a hand? No.
Right. It just sits there, generating, taking its clouds of pixels, its little probabilities, putting it a little bit of chaos, shaking it down like dropping sponges, you know, full of little coloured pixels, kind of paddling along. And it doesn’t stop in the middle of its generation.
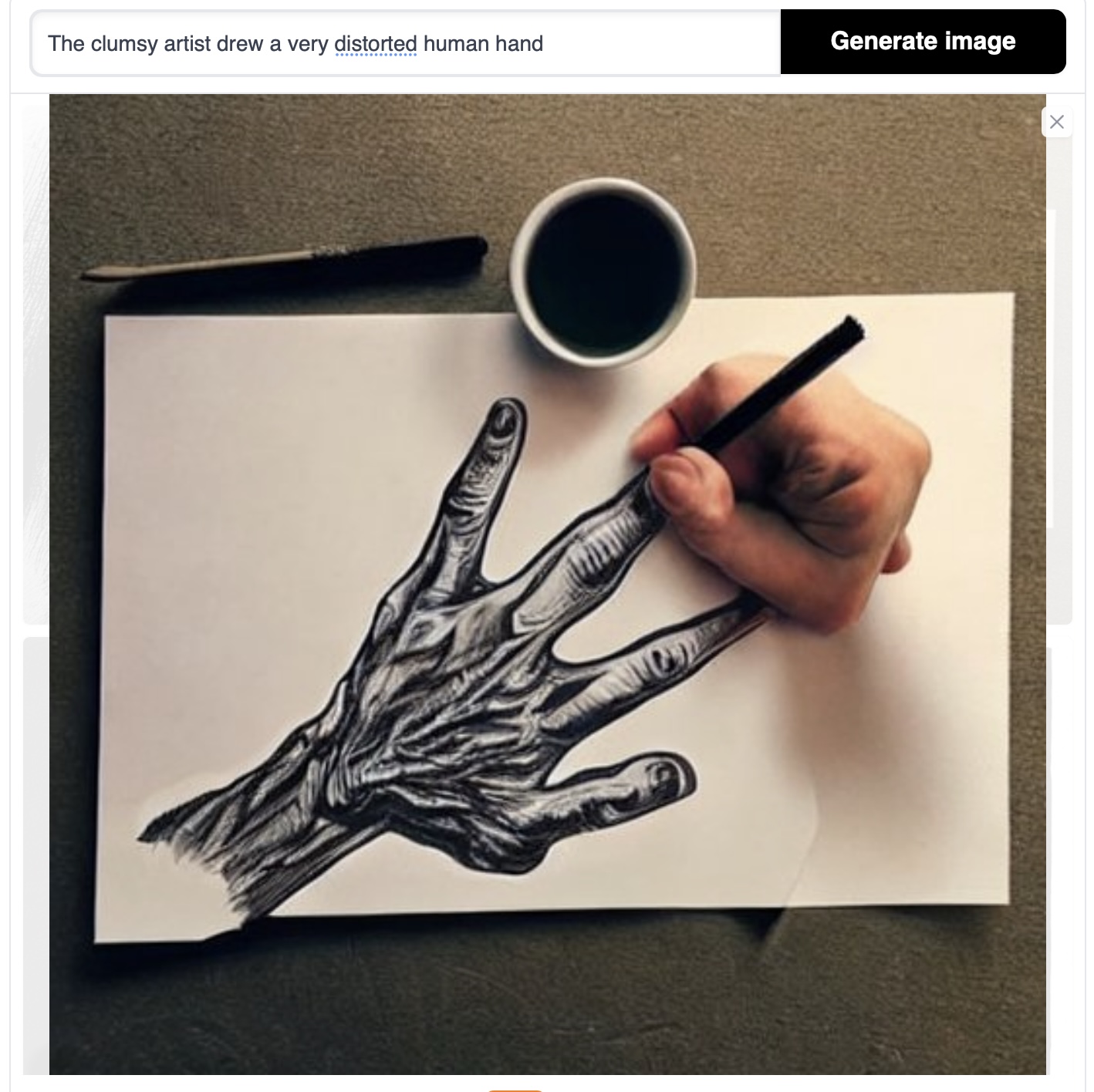
What if I ask to imitate a human drawing a hand? This is one of the most impressive images that I have seen from an image generator. It is unearthly. If you notice carefully you will see that the paper the artist is working on is not square. I love the coffee cup. These are not mistakes. This is the actual grain of its compositional process. And there is a beauty to it. It is not a human beauty. It is a striking image that no human being could ever have dreamt of. It really has presence, it’s surreal.
For the machines that we built, this is their realism. This is what they actually ‘see’ when they are comparing the word ‘hand’ to the most probable JPEGs of hands. And if you think of hands and how fluid they are… We don’t even have a vocabulary for all the positions we can make with our hands. We’re used to them, but we don’t talk about them very effectively. This vocabulary is not in the database because people never described them with enough fidelity, for them to be accurately rendered by a probabilistic engine.
Eventually, they’ll crack the hand problem.

And then when you input something, they’ll just call on the thing that makes the hands and it’ll kind of rush in from the side and powder up the hands quickly and then retreat back into okay, yeah.
When these systems are more refined, they won’t make these elementary errors, but they’re not errors.
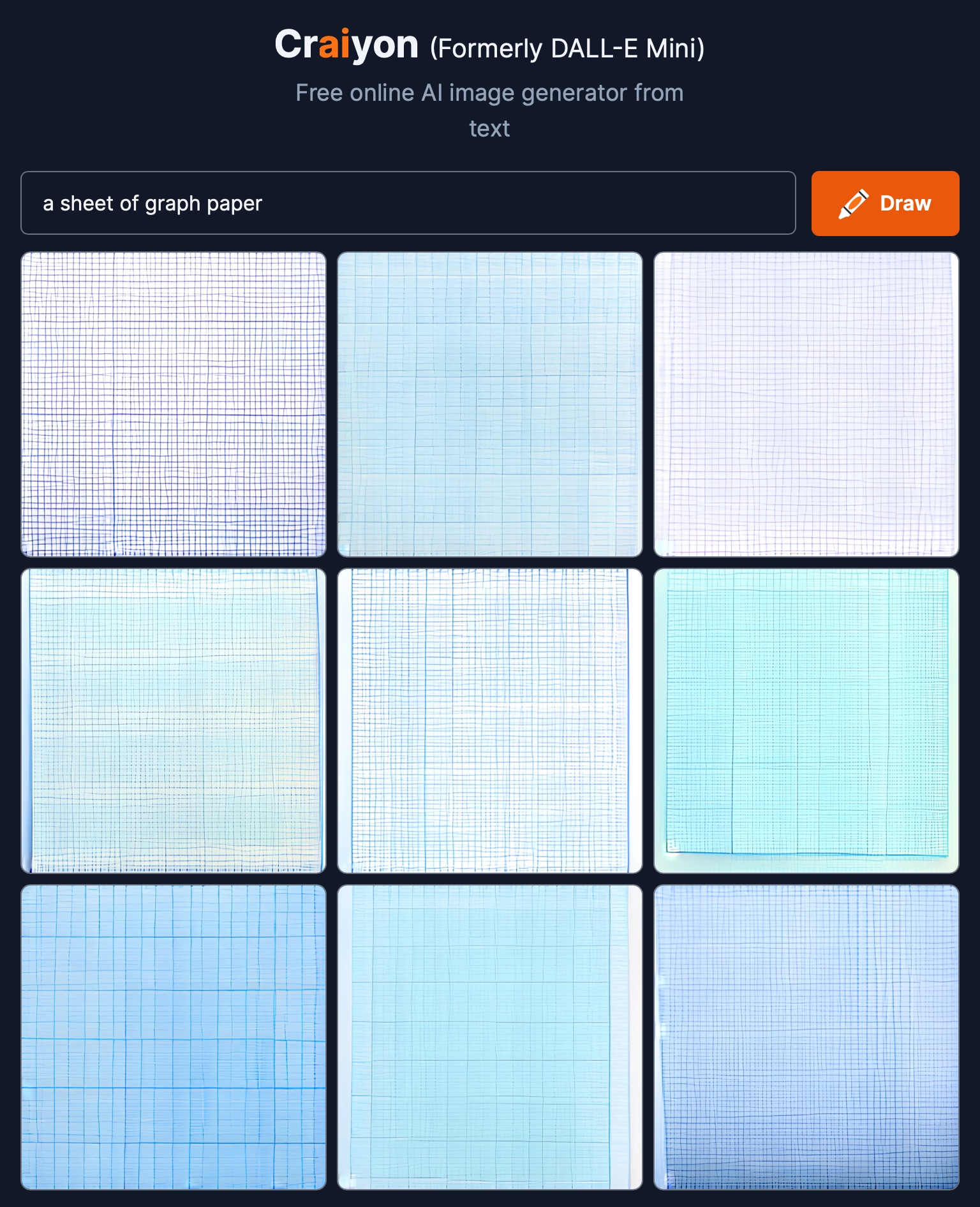
This is graph paper and you would think graph paper would be the simpliest thing to do for computers. The computer sceeen itself is a like a graph, right? If you look carefully there are thousands of tiny probabalistic mistakes in these lines.

They are more obvious when you ask it to do a checkerboard. If you ask to draw a black square, white square, black square, it gets confused. It start doing checkers and then gets lost. Even if you ask it to draw a black and white tile floor it gets lost where black and white is supposed to go, how many there and how it is represented in 3D space, even though there are thousands of photographs of such tile floors online.
Now I’m actually going to do some creative experimentation of my own. And being a novelist. I don’t just want to give it orders to have it make the world’s prettiest picture. Instead, I want to see what it can say about things that humans can’t draw. What will it produce if I ask it to draw something that is beyond human capacity to draw?

For instance, the unimaginable. But the unimaginable is an oxymoron, right? I mean, you can’t draw something you can’t imagine. This thing will draw the unimaginable in a hot second.
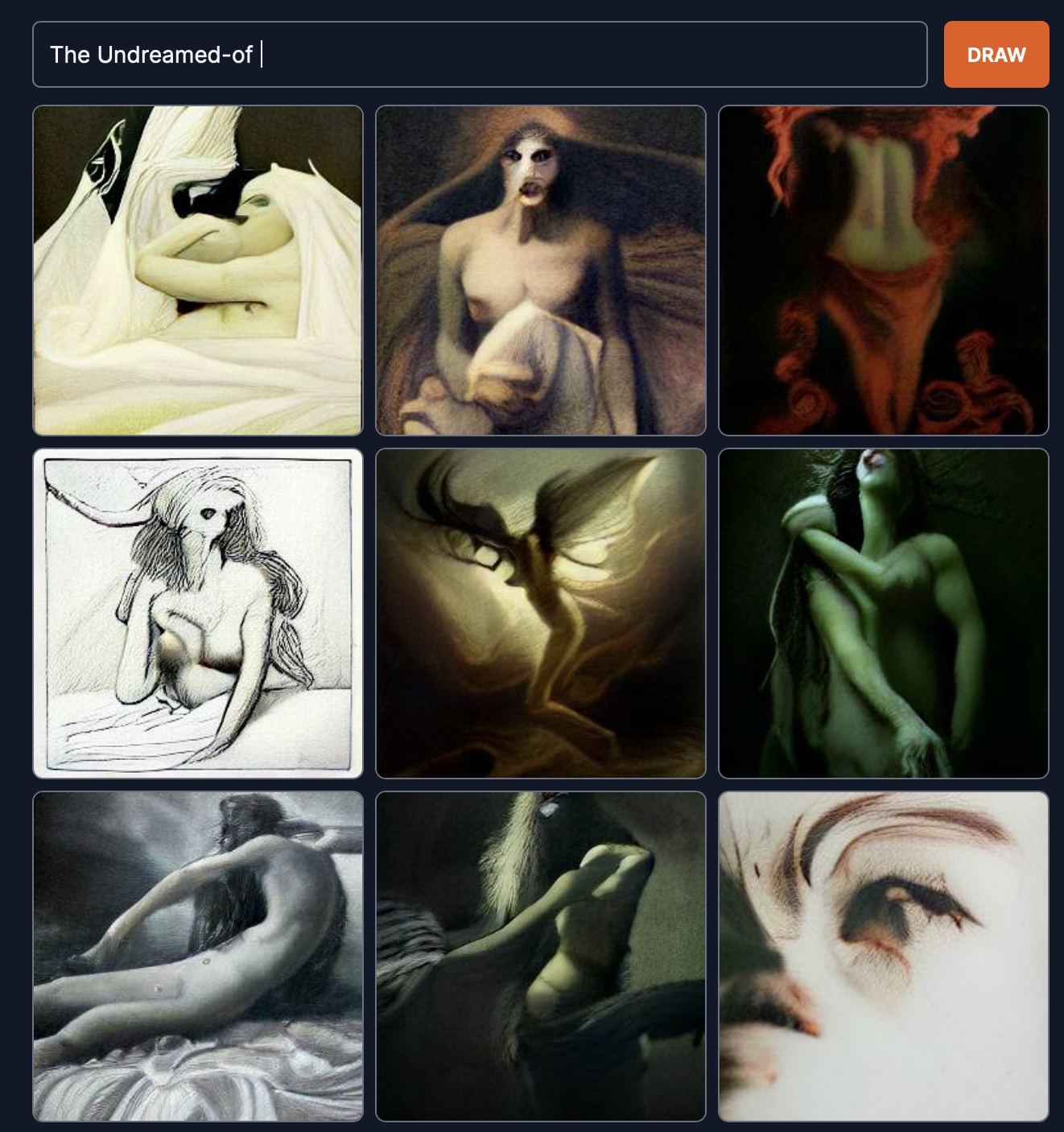
The Undreamed-of. Stable Diffusion doesn’t care. It is perfectly happy.
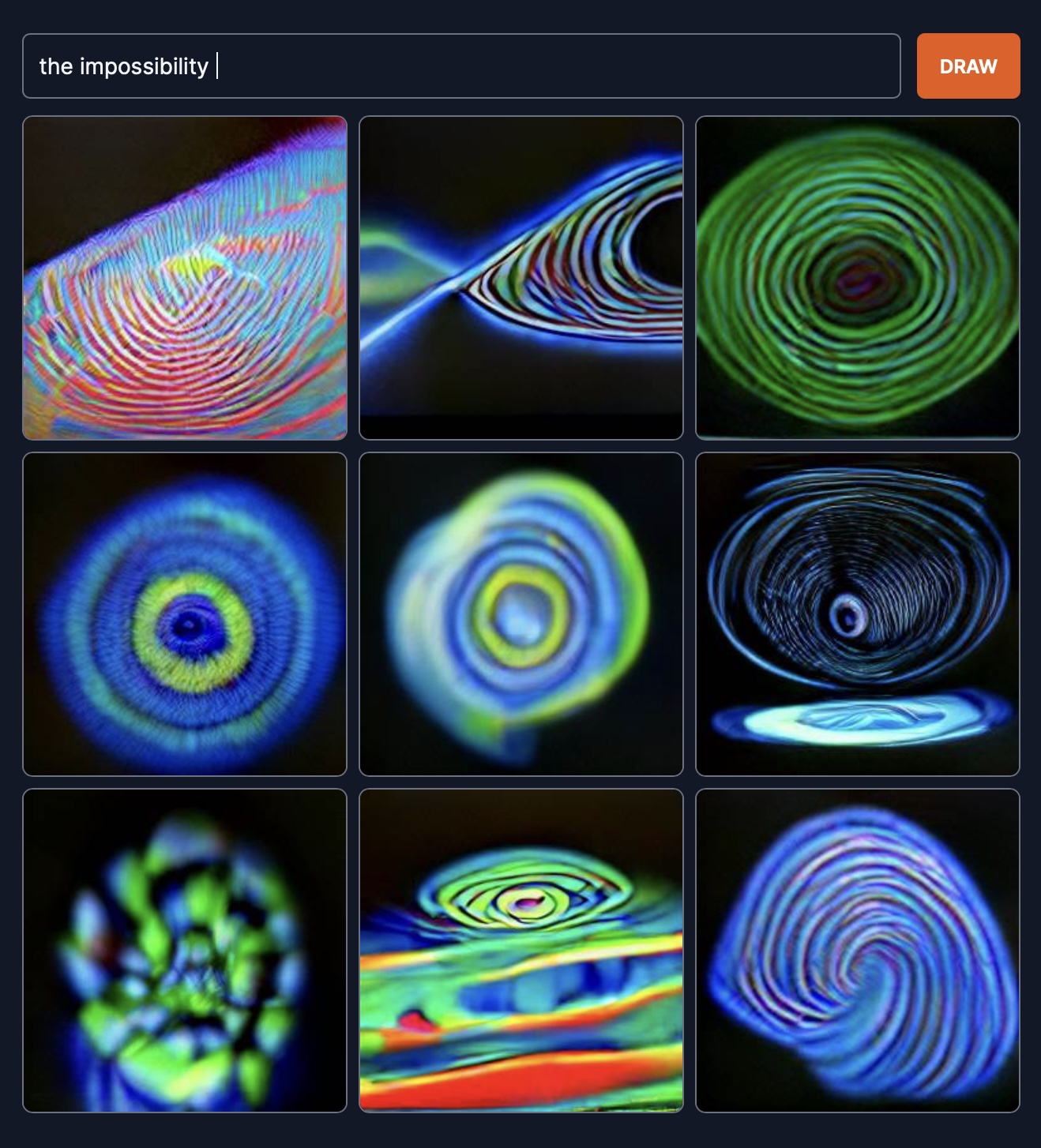
The Impossibility. These are not like expressive artworks, like a Van Gogh. We’re seeing things here that humans can’t make.
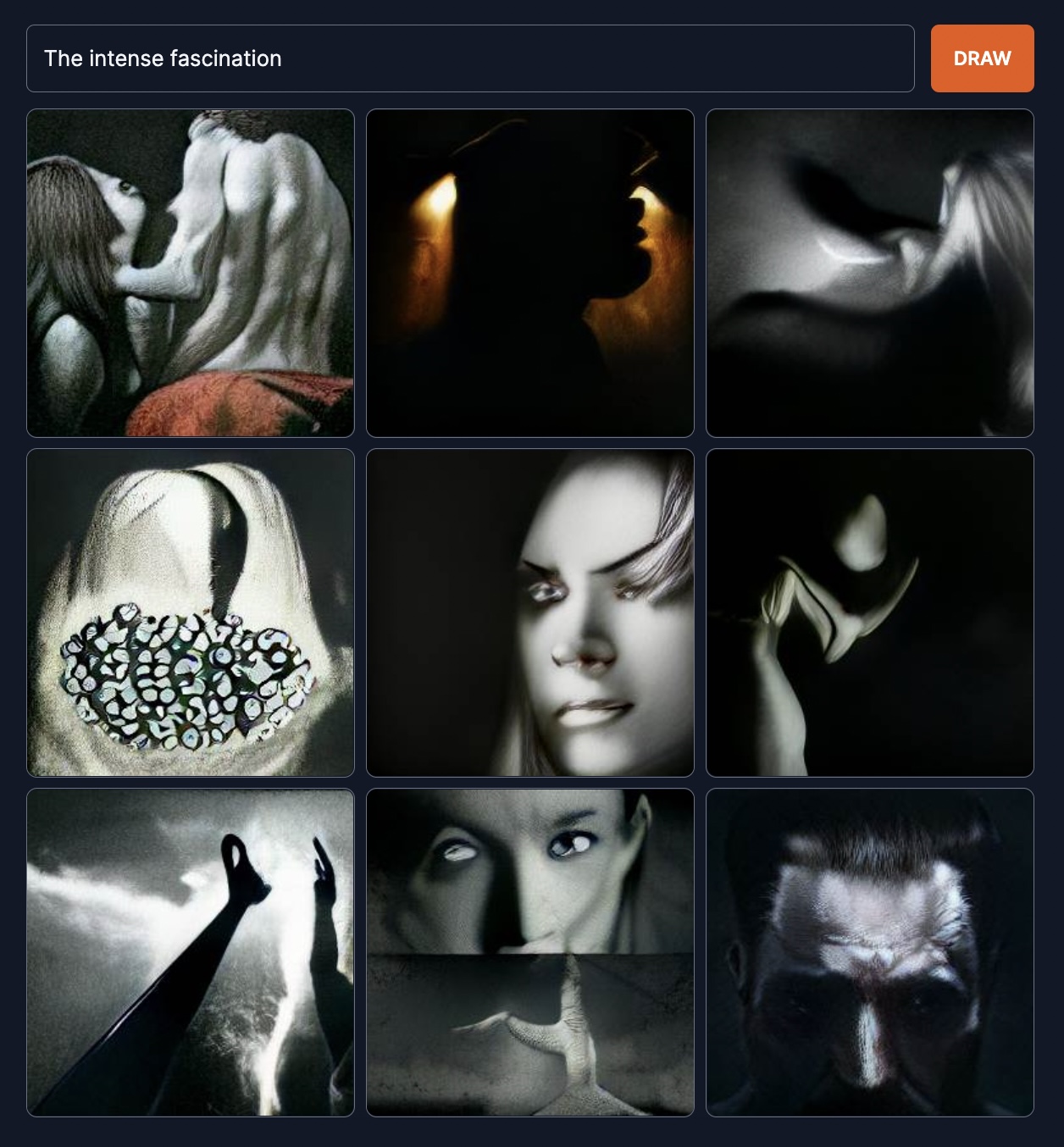
Intense fascination? It doesn’t have any. It doesn’t have emotions.
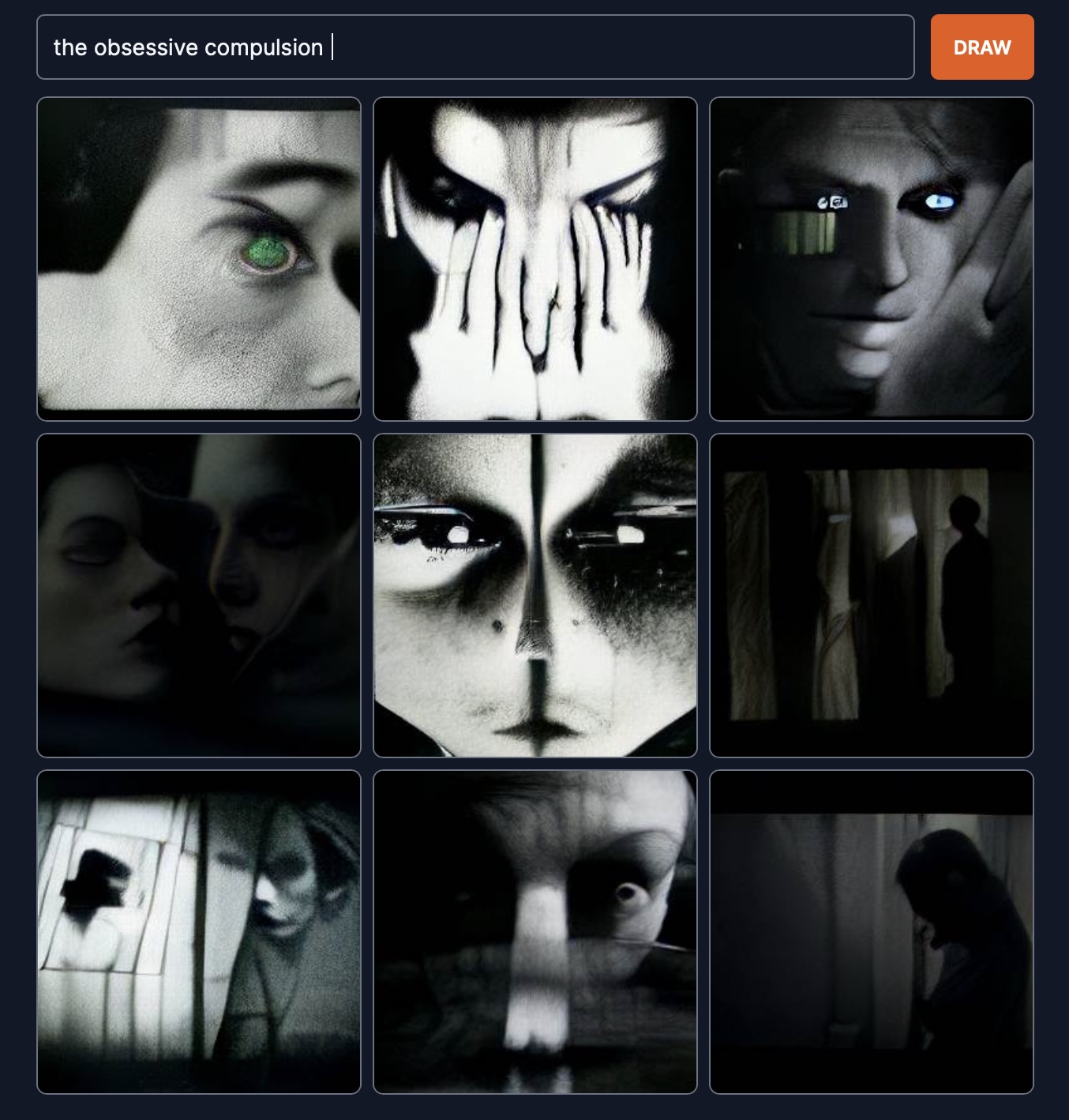
The obsessive compulsion.

The self-referential.
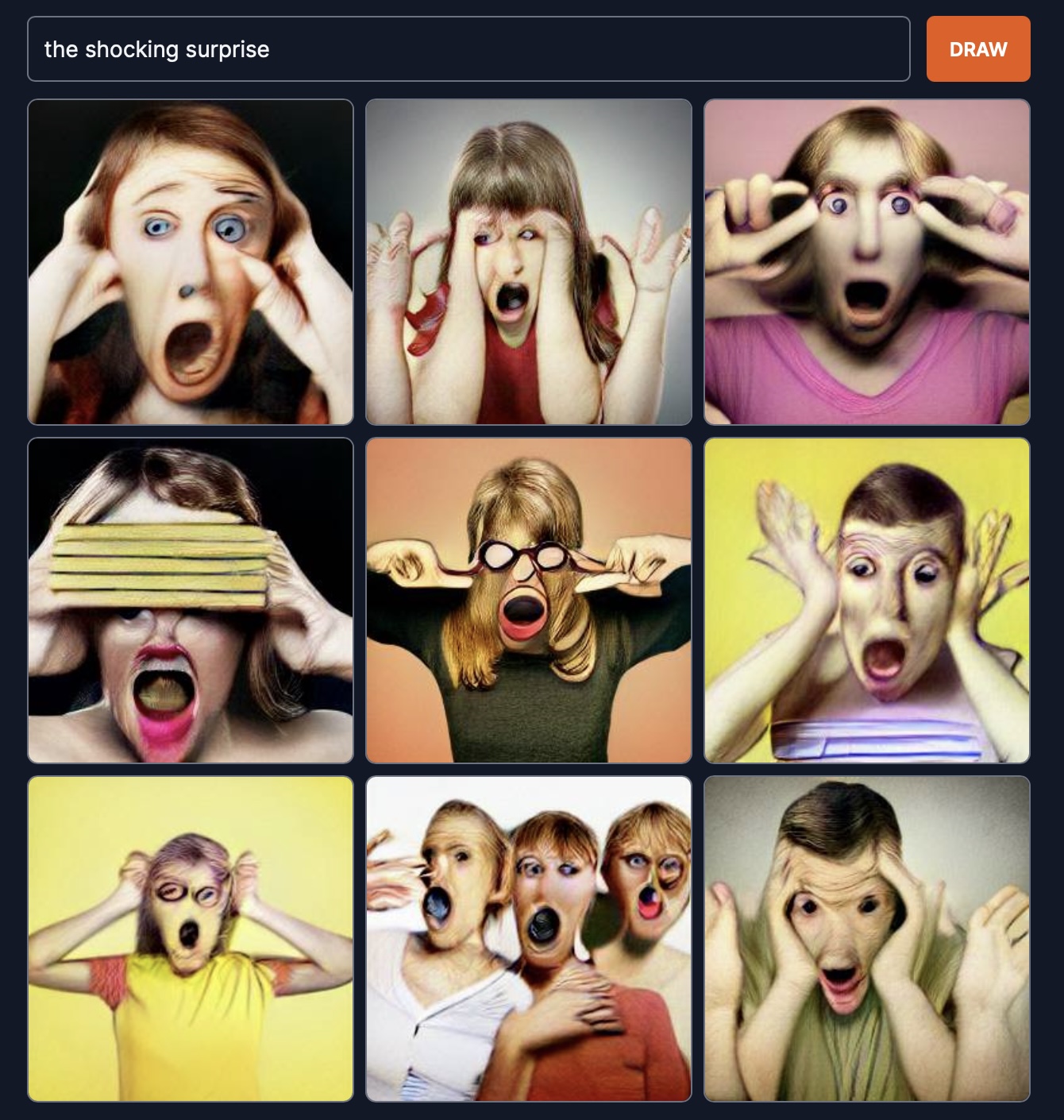
The shocking surprise. It cannot be shockingly surprised and instead is parodying us being surprised.
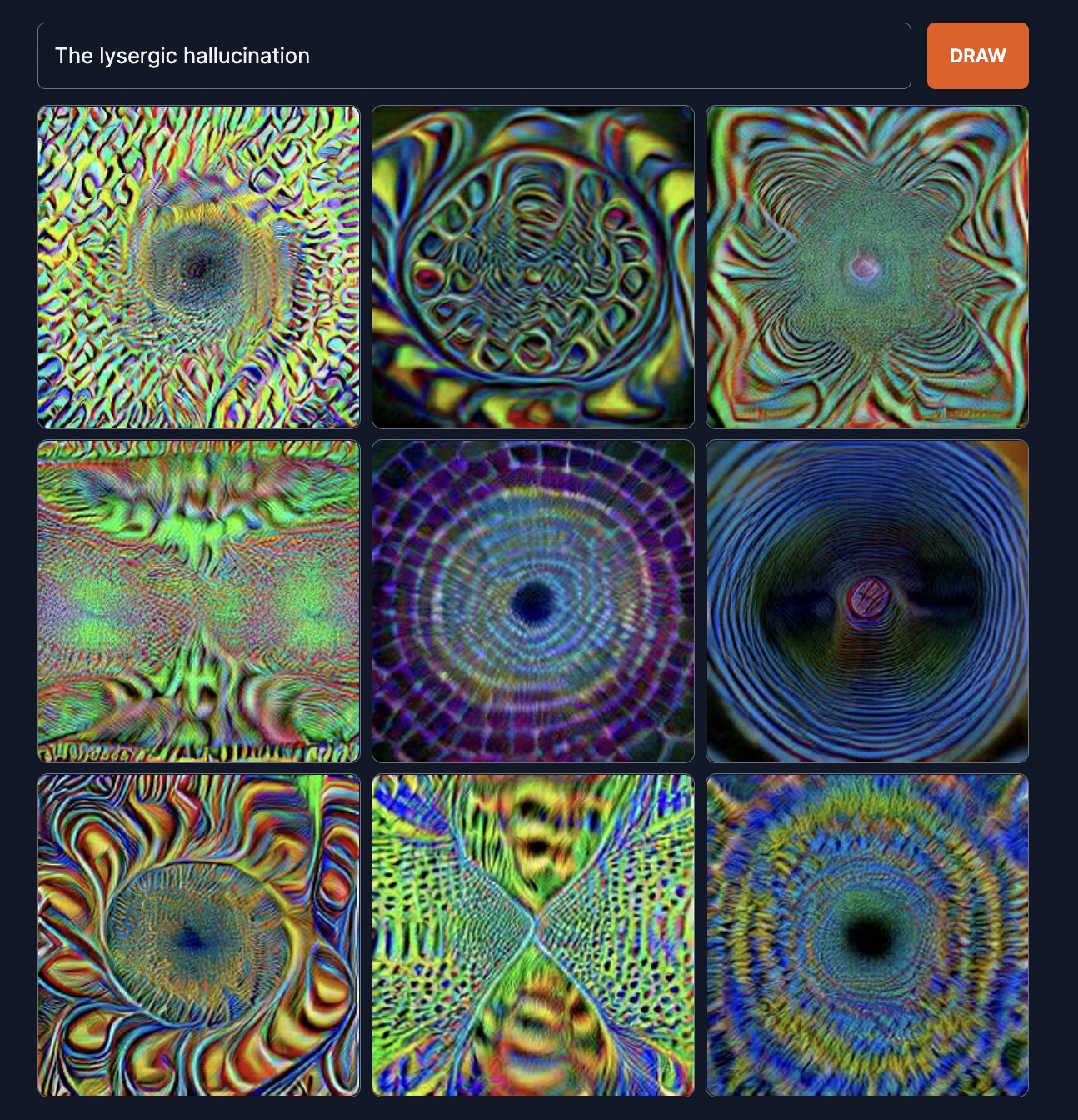
The lysergic hallucination. People have an amber proper about going insane; computers aren’t supposed to be able to do that. It has no trouble whatsoever with psychedelics. It can spin it out by the square kilometre.
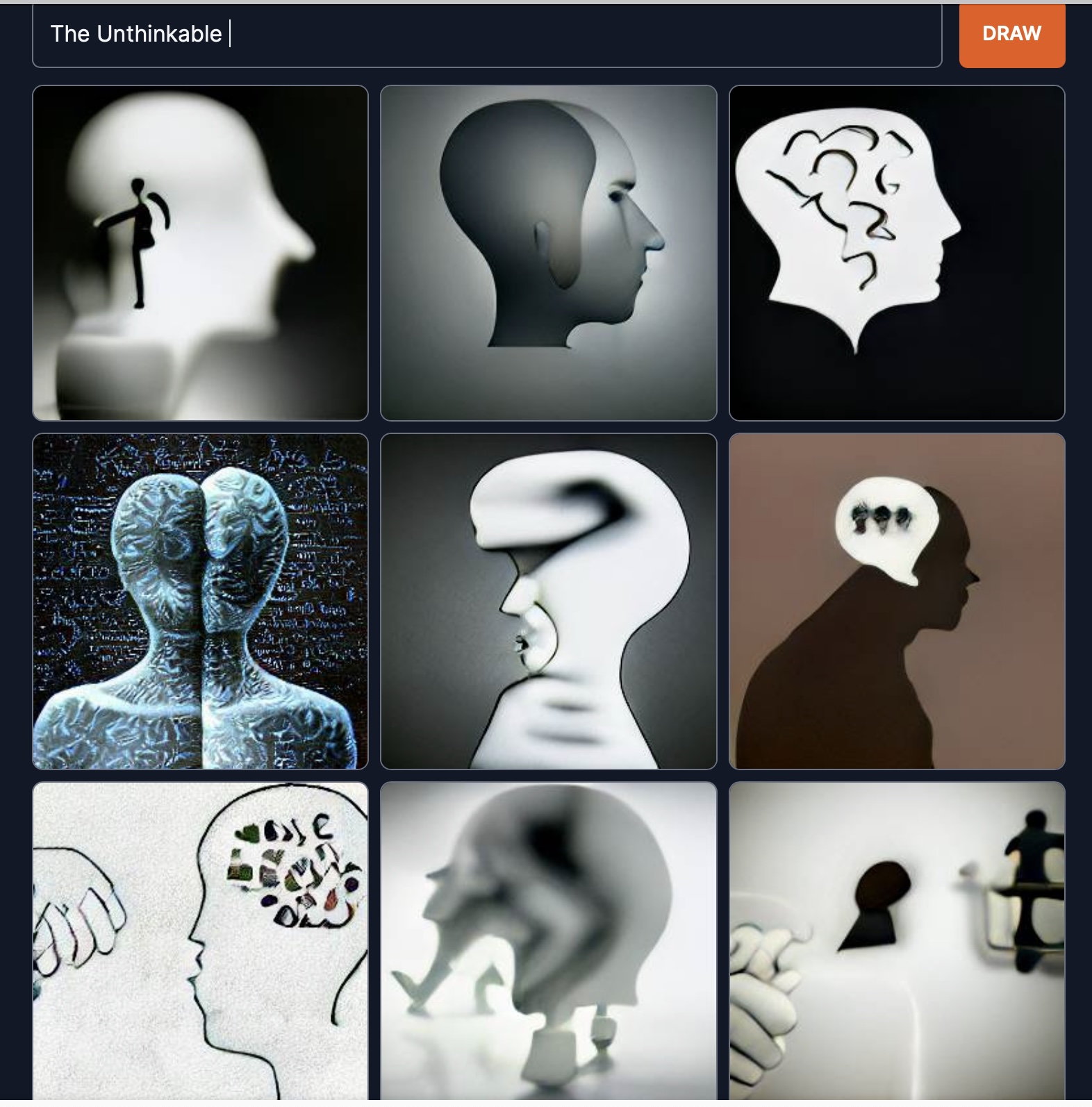
The unthinkable. That is, images of humans being unable to think the unthinkable. It is never able to think. It will always come up with some answer.
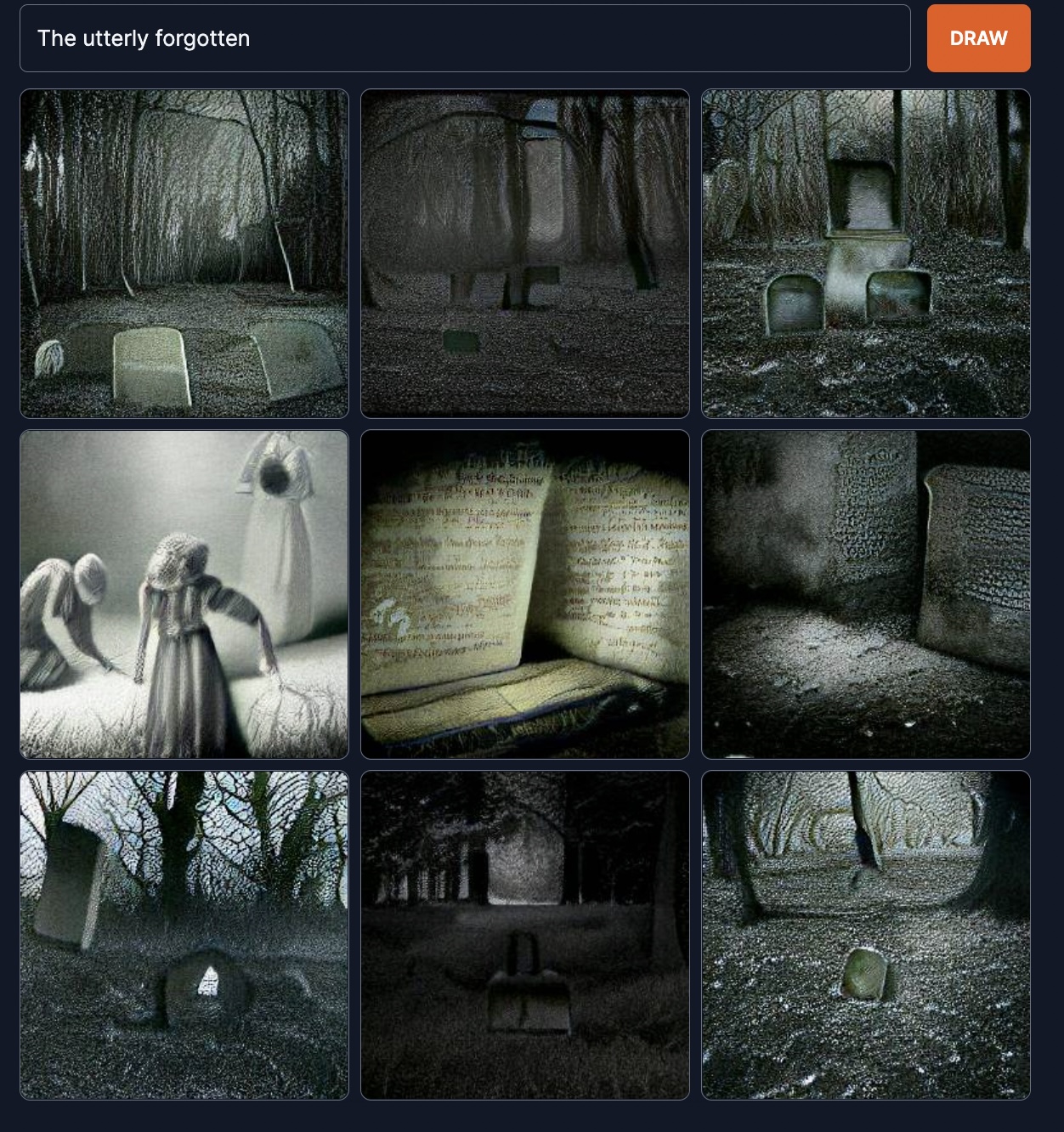
The utterly forgotten.

In the industry, people are particularly interested in what’s called extension or outpainting. So you like to feed it with Hokusai and then you ask what’s on the corner of the painting and it will just add something onto it. Does this look like Hokusai? Yeah, I’ve got lots of this stuff. How about a cherry tree? And this excites graphic artists, It’s like I got a free cherry tree. They don’t recognise that this thing will effortlessly extend and stretch out forever into the direction of infinite cherry trees. You know, a leftover samurai, ninjas, you know, drums, ideograms, whatever. You know, Heian Japan. Weird tales of Genji. It’ll regurgitate that as long as the current is flowing through it, just indefinitely. We’ll never have screens big enough to show it all. It will never get tired of generating pastiches like this, on any scale, at any fidelity. Quickly, cheaply. And without ever making any common sense, without ever getting tired. It will grind these probabilistic connections and spew this stuff out. There is zero creative effort in this. It does take a lot of voltage.

This happens to be a Max Ernst from the 1930s entitled Europe after the Rain. Ernst did a number of these generative experiments. First, he went out with his canvases and rubbed pencils on them in order to get suggestive forms, and then he would paint over them. And then later he decided he’d just take the paint itself and toss it onto the canvas, stomp on it, and then open it up like a Rorschach block and paint over it. So he’s a world-class surrealist artist, so he got this smashed-up paint with not random, but suggestive kinds of imagery. He did a series of these surrealist paintings, which are some of his most successful ones. They are nearly 100 years old now, and they never look like anything else. Eventually, the novelty tired Ernst. He did a number of these gimmicks and he came to feel it was kind of beneath him. He got all the benefits out of this particular trick that he was likely to have and then moved into a different phase of his expressive career. It’s not like generative techniques have never entered the fine art world before.

This is Meret Oppenheim’s Breakfast in Fur, which will never be looked at the same. And this is something that troubles me. If you show this to anyone who has never seen henceforth next year, if you show this to anyone who is unaware of this famous artwork, almost a hundred years old. They will immediately conclude that it was generated. They will never look at it again and think, what a cool, surreal thing. It’s like she took a teacup and wrapped it up in gazelle fur. And look, she even wrapped up the spoon. And you know what? You can’t even drink out of that teacup. Think of putting tea in there, picking it up and feeling that fur in your mouth. Ooh, ooh. What a surrealist frisson. Boy, that’s super weird. Such an artist, this Meret Oppenheim. Such a form of human expression. We may have opened Pandora’s box and slammed the gate on our heritage.

There’s a quote by Simone Weil: “The beauty of the world is the mouth of a labyrinth,” which is a warning: if you’re interested in aesthetics, you have to curate stuff or happen to be an art director of a festival (like I am), you can’t just pick the pretty ones. The beauty of the world is the mouth of a labyrinth. Once you start taking aesthetics seriously, you enter metaphysics. The world comes up with these labyrinths and if you look at them they’re statistically likely portraits of labyrinths that are not, in fact, labyrinths. A labyrinth has a place where a human goes in and then the human is supposed to get bewildered. He takes a lot of false steps and he makes a lot of mistakes and he has to retreat often. But eventually, there’s a hole out the other side. He comes out and says: oh, such a cool experience. I was in the labyrinth. I thought I’d never get out. But then when I did get out, I was really happy to, like, defeat this puzzle. It doesn’t know what a puzzle is. It doesn’t know what legs are. It’s just looking at all the databases of the labyrinth that it has, which is very extensive. It draws on something that looks like a labyrinth but isn’t. And yet it’s beautiful, a beauty which is not of this world.
That’s what beauty is. The beauty of the world is the mouth of a labyrinth. This is beauty, which is not of this world and cannot be judged by the standards of beauty that we had earlier. But I know that this labyrinth is my doom. I don’t know how long I’m going to have to put up with this. I’ve been in the labyrinth of artificial intelligence since I first heard of it. I’m not too surprised that there’s suddenly a whole host of labyrinths. Thousands of them. I don’t mind. I know it’s trouble, but it’s kind of a good trouble. I don’t mind living there. I’ll build a house in the labyrinth. I’ll put a museum in it. You’re not going to stop me. I’m happy to accept the challenge. I hope you’ll have a look at it.
—
Transcription: Amberscript. Editing: Geert Lovink