In September 2019 I visited Linz (Austria), the UNESCO City of Media Arts, where I attended the 40th Anniversary of the Ars Electronica Festival, 'the most time-honored media arts festival in the world,' with its special theme ‘Out of the Box: The Midlife Crisis of the Digital Revolution’. As I nibbled on gummy candies that had been thrust upon me to promote the Sparkasse bank by teenage volunteers at cafés, I expressed myself with the muscular contraction mechanisms and skin appearance movements of my face. As I climbed the stairs to the rooftop of the OK Center for Contemporary Art, where Ukrainian multidisciplinary artist Alexander Ponomarev’s twenty-meter and two-ton The Flying Ship sailed above the city skyline, my facial expressions feedbacked information to my conscious self about my emotional experience. And as I lifted a sunflower high to the stars during Solar: Towards the Sun, staged by British-Polish opera director David Pountney, which brought together scenic effects, music, fireworks, and dance in a Visualized Soundcloud, I empathized with what the people around me were feeling by mirroring the expressions on their faces with my own.
Walking about the Ars Electronica Center, OÖ Kulturquartier, and Post City, I became curiouser and curiouser. And this in turn quickened the behavioral dynamics of my facial expressivity. All around me was a familiar face, my own face, reflected back to me in the media art like at some kind of carnival funhouse. Through the seemingly infinite labyrinth of Festival buildings, passages and rooms, I encountered more than half a dozen works of what I term ‘biometric art’ that used facial recognition technology (FRT) and automated facial expression analysis (AFEA). To classify this art form according to its common characteristics, ‘facial recognition art’ is one among the several ‘biometric arts’, which intersect and overlap with many other art forms within ‘media art’, while also sharing formal elements with many ‘traditional arts’. With facial recognition both how the artwork is made and what it is about, biometric art to one degree or another performs the act of recognition in order to critically reflect upon the most advanced science and technology about the face today.
Putting People in Classificatory Boxes
Facial recognition has increasing been in the news of late from Shalini Kantayya’s Coded Bias investigative documentary to John Oliver’s Last Week Tonight television satire. But beyond such popular media, the past few years have been a breakout period for biometric art that uses facial recognition. A decade after the emergence of the earliest biometric artworks based on facial recognition technology around 2007, awards, exhibitions, and festivals are starting to be dedicated to this contemporary art form. At the 40th Ars Electronica Festival, such biometric artworks included, for example, Argentinian media artists Elia Gasparolo and Joaquín Fargas’ Robotika: The Nannybot, a cyber nanny that uses facial recognition to learn how to take care of a human baby, which would ‘assist in the preservation of the human species’ as a kind of ‘Galactic Ark’ if ‘the end of human civilization arrives in a near or distant future’. But this year, Ars Electronica also established a new award category, ‘Artificial Intelligence & Life Art’, for the Prix Ars Electronica, known as the Golden Nica. And a biometric artwork was awarded honorary mention, Israeli media artist Mushon Zer-Aviv’s The Normalizing Machine, an interactive installation in which ‘each participant is asked to point out who looks most normal from a line-up of previously recorded participants’, as machine-learning ‘analyzes the participant decisions’, and ‘adds them to its’ aggregated algorithmic image of normalcy’. Such a presence of works at Ars Electronica points to how biometric art is beginning to be acknowledged in the canons and timelines of art history and visual culture.
Enlarge

Elia Gasparolo and Joaquín Fargas, Robotika: The Nannybot, 2019. Exhibition view from Post City at the 40th Ars Electronica Festival. Photograph by the author with permission
In 2019, biometric art using facial recognition even made an appearance at the 58th International Art Exhibition of the Venice Biennale with its special theme ‘May You Live in Interesting Times’. Historically, the Biennale has tended to be a venue for traditional art forms rather than for new media art. Although works of biometric art have certainly been accepted to the Biennale in previous years, such as in 2015 with Dutch media artists Karen Lancel and Hermen Maat’s Saving Face in the China Pavilion at the 56th Biennale. This year, however, a work of biometric art was tailored to the Palazzo delle Prigioni, a Venetian prison in operation from the sixteenth century until 1922, recalling the panopticon designed by Bentham. There in the Taiwanese Pavilion, Taiwanese pioneering net artist and filmmaker Shu Lea Cheang installed 3x3x6, the title of which refers to the standard architecture for industrial imprisonment, a 3x3 square meter cell monitored continuously by six cameras.
For this biometric artwork, Cheang was inspired at least in part by today’s application of facial recognition technology for identifying sexual orientation on the basis of face. In this kind of ‘AI gaydar’, a deep neural network learns how to identify gay from straight women and men from nose shape and grooming style, facial features consistent with the prenatal hormone theory of sexual orientation and related gender-atypical facial morphology. However, as Paul B. Preciado writes in his curatorial statement, ‘if machine vision can guess sexual orientation it is not because sexual identity is a natural feature to be read [but because] we are teaching our machines the language of technopatriarchal binarism and racism’. In 3x3x6, Cheang used a customized facial recognition system with an ‘internal network of 3-D surveillance cameras [which] transforms the panopticon into a tower of sousveillance’. Virtual online exhibition visitors submit their selfies, which are then combined with the face images of real-world exhibition visitors as well as face images of those individuals who have been ‘criminalized by sexopolitical regimes’, this entire image set is then ‘transformed by a computational system designed to trans-gender and trans-racialize facial data’. Thus, visitors become surveiller and surveilled, voyeur and object, watcher and watched, as they question their own participation in panoptical systems, willing or not.

Enlarge

Of course, the face has long been used in society for putting people into boxes made from diagnoses, labels, or symptoms, as well as to constrain or even determine potential interpretations for their behavior through the attribution of causal laws and the assignment of universal classifications. In several recent cultural exhibitions, visitors could experience current biometrics in conversation with classical physiognomy through curations that brought together art, science, and technology from face studies both historical and contemporary. These exhibitions include, for instance, the STATE Festival for Open Science, Art, and Society’s ‘The State of Emotion: The Sentimental Machine’, as well as The German Hygiene Museum’s ‘The Face: A Search for Clues’. Significantly, these exhibitions address how the formal design for recognition technology may employ many of the same logical fallacies as physiognomic inference, such as presuming a stable, binary one-to-one correspondence between physiological behavior and psychological phenomena. As Meredith Whittaker and Kate Crawford state in the AI Now Report 2018, the ‘idea that AI systems might be able to tell us what a student, a customer, or a criminal suspect is really feeling or what type of person they intrinsically are is proving attractive to both corporations and governments,’ despite the fact that ‘the scientific justifications for such claims are highly questionable, and the history of their discriminatory purposes well-documented.’
One of the earliest cultural exhibitions to not only contemplate but also concentrate on facial recognition technology was ‘Facial Recognition’ curated by Joes Segal at the Wende Museum in Culver City, California, in 2016. The exhibition included reproductions from historical research about the face, trial demos for recognition technology, and media artworks that either use recognition technology or are about it. Founded in 2002, The Wende is named after the German phrase seit der Wende (‘since the Wall fell’). The Museum specializes in art from the Cold War and former Communist Bloc countries. And it is within this socio-political context that Segal curated his exhibit about the ways in which ‘one of the paradoxes of life today is that we are forced to decide how much personal freedom to surrender in order to strengthen our sense of safety’.
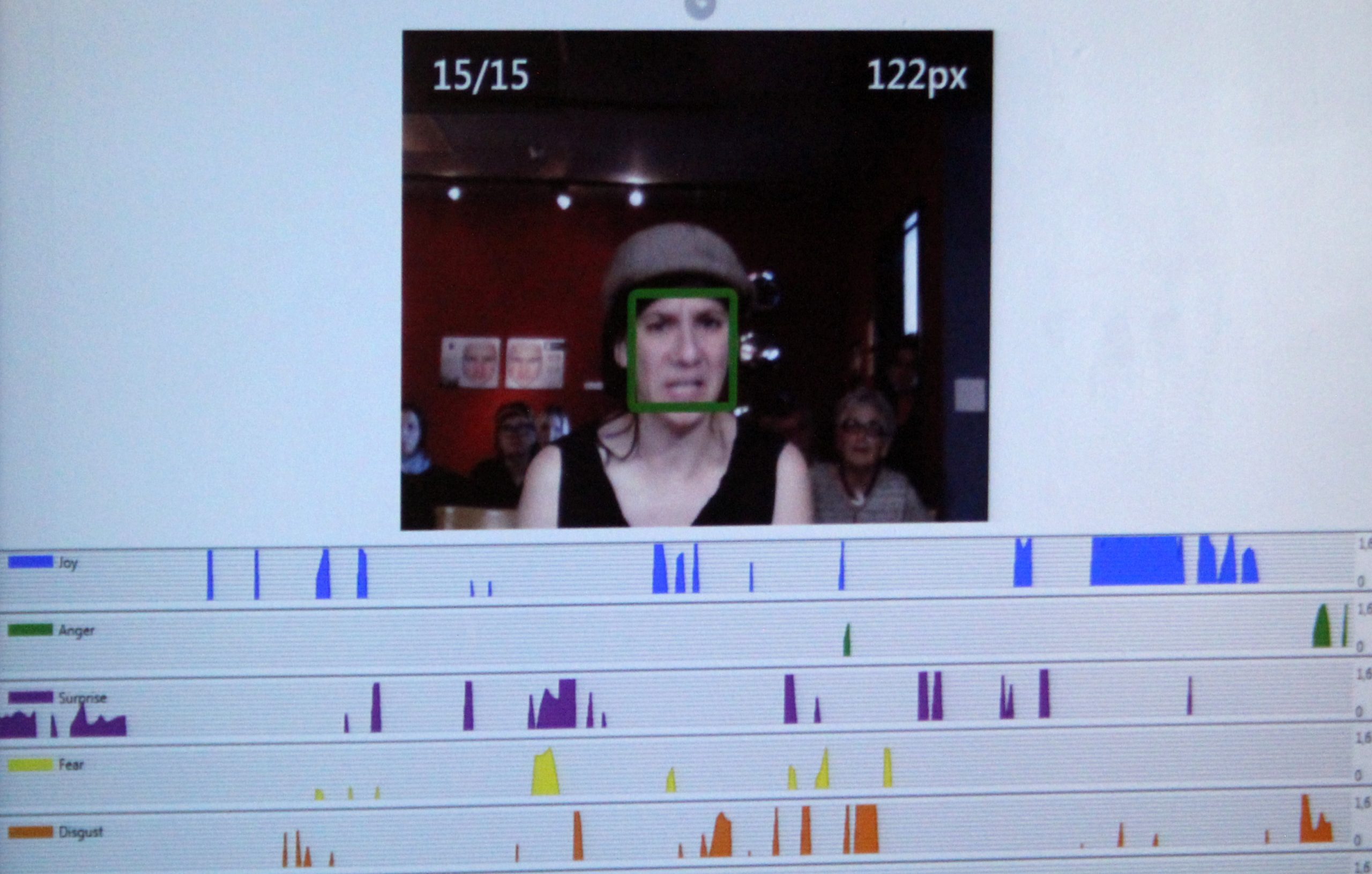
Enlarge
Computing Facial Behavior into Data Capital
Today, facial recognition technology has proliferated to the point of being omnipresent. Eye-in-the-sky surveillance systems equipped with facial recognition using active and passive artificial intelligence, ambient intelligence (AmI) or distributed artificial intelligence (DAI), are becoming integrated on buildingwide, citywide, nationwide, and even worldwide levels. For many developed countries, federal legislation aims to promote the application of facial recognition technology in for instance criminal justice, domestic entry-exit, and immigrant enforcement. Yet, this ubiquitous application of facial recognition has raised concerns regarding accountability and transparency, especially given the overall absence of ethics laws and regulation. For instance, in 2019 San Francisco became the first major city to ban the use of facial recognition technology, even by its own government agencies and law enforcement. As the board of supervisors wrote in this city ordinance, the ‘propensity for facial recognition technology to endanger civil rights and civil liberties substantially outweighs its purported benefits’. And less than a year later, in response to the Black Lives Matter movement and global protests against police violence, more and more institutions are beginning to re-assess the potential harm of facial technology using artificial intelligence, calling attention to its hazards and risks, and proposing guidelines to politicians, practitioners, and the public for the ways in which it should work and be used in society.
Over the last decade, a number of media artists have challenged the ubiquitous application of facial recognition in public spaces or social media by big government and big tech, employing activist strategies of counter or inverse surveillance, whether ‘hacktivism’ as first coined by cultural writer Jason Sack, ‘sousveillance’ as first termed by wearables engineer Steve Mann, or some other critical practice. For example, in 2011 with Face-to-Facebook, third in the Hacking Monopolism Trilogy, Italian media artist Paolo Cirio and media scholar Alessandro Ludovico used facial recognition to create a dating website which ‘talks about the consequences of posting sensitive personal data on social network platforms’. In their own words according to their artist statement, first the artists web-scrapped one million profile pictures from the social network Facebook. Then they established categories that described the faces in these profile pictures that they believed to be among ‘the most popular that we usually use to define a person at a distance’, ‘without knowing him/her’, and ‘judging based only on a few behaviors’. These classifiers included ‘climber’, ‘easy going’, ‘funny’, ‘mild’, ‘sly’, and ‘smug’, with ‘some intuitive differences, for both male and female subjects’. And finally, Cirio and Ludovico applied ‘custom-made’ facial recognition trained on these classifiers to the images.
In 2008 when Cirio and Ludovico began developing the Face-to-Facebook, facial recognition using artificial intelligence was only just starting to become commercially available for non-expert users. Therefore, as Cirio once explained to me, they bought a facial recognition algorithm ‘from an Italian coder who had one of the few available worldwide’. Customizing this software in the MATLAB computing environment and programming language developed by MathWorks, Cirio and Ludovico ‘selected forty samples for each category in an “arbitrary” way based on how they appeared’ in order to train their neural network. The facial recognition then proceeded to successfully classify 250,000 profile pictures from their web-scrapped dataset. After sharing these images on a dating website, ‘www.Lovely-Faces.com’, the media artists received ‘worldwide press coverage of more than one-thousand media outlets from all over the world in just a few days’ as well as three cease and desist letters from Facebook. By taking a ‘critical action against a giant online corporation’ that ‘shows how fragile and potentially manipulatable the online environment actually is’, Cirio and Ludovico positively changed the public conversation about privacy settings on social media. In fact, after Face-to-Facebook, Facebook proceeded to completely overhaul their privacy settings.
Like any technology, facial recognition is ‘neither good nor bad; nor is it neutral,’ as Melvin Kranzberg stated first in his six ‘laws of technology’. Whether and to what extent this technology is being applied successfully, let alone justly, is entangled with the logic by which it becomes operable. Certainly, recognition technology affords for new ways of producing knowledge about human attitudes, behaviors, events, and preferences. Retrieved patterns from the past are used not to regulate people of the present but to requisition potentialities for the future. In other words, the face is used principally for doing predictive analytics. At its most reductive, recognition technology may be described as a system of logic by which complexity is organized and predictability is operationalized using standardized explanatory models. And this use of techno-labor for extracting data capital from the face is accelerating. However, such data behaviorism poses complex ethical dilemmas in part because the focus is on data models rather than concrete agents.
Some biometric artworks reflect on this very issue of data behaviorism, such as Zach Blas’s 2011 Facial Weaponization Suite and Trevor Paglen’s 2017 (Even the Dead Are Not Safe) Eigenface. Or, for example, in 2013 with his series of Data-Masks, American media artist Sterling Crispin experimented with ‘how machines perceive human beings – reducing them to general recognition features, abstracted from their actual appearance’. As he explained in his master thesis, these 3D-printed nylon facial masks, mounted on 46x66 cm mirrors, were created by reverse engineering facial recognition technology. Through this art-based research, Crispin found that these applied face studies do not approach the face as an actual object or real thing but, rather, the face is already conceptualized as data. In applications of facial recognition technology, as Felicity Coleman and her colleagues state in Ethics of Coding: A Report on the Algorithmic Condition, there is little to no distinction made between the sign for a thing and the thing itself. And because of the efficiency and immediacy of facial recognition, much like the old adage res ipsa loquitur, the face data appears to speak for itself.
But there is more to facial recognition than meets the eye. And this technology should not be taken at face value. As Björn W. Schuller contends, an important aspect of what is lost in the datafication of the face is the possibility for rigorous scrutinization into how political languages and power relations become integrated within recognition technology. In contrast to ‘traditional images’ which are the ‘observation of objects’, as Vilém Flusser articulates, these ‘technical images’ are the ‘computation of concepts’. Consequently, the preferences, prejudices, and priorities of the agents that shape these concepts may lead to algorithmic biases in the technology. To understand such an image, one must look beyond its surface, and to the entire process of how information is being made visible. This is where biometric art comes in: to critically reflect upon the potential for the abuse of technology and the misuse of face.
Among the many faces of facial recognition, this technology can be used to discriminate gender and race. In 2018 with Gender Shades, Ghanaian-American computer scientist Joy Buolamwini evaluated the potential algorithmic biases in facial recognition technologies from Microsoft, IBM, and Face++ with respect to demographic subgroups including female and male as well as phenotypic subgroups from darker to lighter skinned. She found that ‘all classifiers performed better on male faces than female faces’, as well as ‘lighter faces than darker faces’, and that ‘all classifiers perform worst on darker female faces’. Buolamwini exhibited Gender Shades in 2019 at the 40th Anniversary of the Ars Electronica Festival. And, as the founder of The Algorithmic Justice League, Buolamwini also testified before the U.S. Congress on gender and racial bias in recognition technology in May 2019. When questioned by congresswoman Alexandria Ocasio-Cortez (D-NY), Buolamwini asserted that ‘pale, male data sets are being used as something that is universal when that is not actually the case when it comes to representing the full sepia of humanity’. In addition, the error rate and false positives are disproportionately high among non-white demographics. And there is the issue of ‘confirmation bias’, where if someone has ‘been said to be a criminal’ in the past, they are ‘more targeted’ in the future by government agencies using facial recognition.

United States House Committee on Oversight and Government Reform, Hearing on Facial Recognition Technology: Its Impact on our Civil Rights and Liberties, May 22nd, 2019. Used with permission from C-SPAN.
Perhaps one of the most significant elements that makes a difference in the way recognition technology works is its classifier. A classifier is a predictive model developed from a set of images that is used to map from input variables to output variables. It is a concept about why the face makes signs, by what carriers or vehicles in the face these signs convey meaning, and how these signs might be interpreted. In recognition technology there is a wide palette of such categories, labels, or targets, as the classifier is variously termed in the computer sciences. Many biometric artworks investigate the role played by such classifiers in society. The classifier may include, for example: ‘one of the 150 pre-selected persons in the data base: all chosen for their controversial or infamous acts’, as in Dutch installation artist Marnix de Nijs’ 2008 Physiognomic Scrutinizer; or one ‘of 43 students from the Ayotzinapa normalista school in Iguala, Guerrero, Mexico’ who were kidnapped in 2014, as in Mexican-born technological performance and theater artist Rafael Lozano-Hemmer’s 2015 Level of Confidence. In each of these works of biometric art, the classifier is what the faces of the viewer, participant, or interactor are compared to and matched with as the biometric artwork performs facial recognition.
Designing the First Biometric Artworks
On the face of it, there is great diversity between these works of biometric art based on facial recognition technologies. But in many if not most biometric artworks, the audience to one degree or another experiences their own face while it is being recognized. And the primary artifact, image, or object that constitutes the work itself principally consists of the matching from data to individual, as the face of the person interacting with the work is compared to the face of the classifier archived in a database. That is, as Ksenia Fedorova analyzes, the audience and their face act upon the artwork, which itself affords for this interaction, enabling a multipath informational exchange between artwork and audience, whereby the artifact, image, or object changes somehow in response to this interactor or participant. Because of the way facial recognition works, this basic design is relatively consistent across biometric art.
Essentially, a biometric artwork is an intelligent machine. As Frieder Nake argues, such an art form consists triadically of a subface, interface, and surface. The subface is the program or software that runs on a computer, in this case the facial recognition using artificial intelligence, as well as the machine or hardware that executes a code. The interface is the shared boundary across which the separate components of this system exchange inputs. And the surface is the output device that generates an image or other effects from this code. In a biometric artwork, therefore, facial recognition technology is but one material out of many that has been intermedially combined by the artist, multi-artist collaboration, or interdisciplinary group. As Irina O. Rajewsky examines, with intermedial combination, each form of articulation plays a role in determining the media specificity for the newly formed object and, in turn, contributes to its signification. Thus, hybridized into the biometric artwork may be analogue as well as digital media, not only sensory but also computable information, human participants and machine provocateur, all within a complimentary generative process of becoming.
Biometric art that uses facial recognition emerged in the early twenty-first century, with the first such artwork made around 2007. However, the contemporary history of this art form goes back to the beginnings of recognition technology in the mid-twentieth century, and to the first public exhibition of an automated facial recognition system at the 1970 World Exposition held in Japan. With support from The Nippon Electric Company (NEC), Japanese electrical engineer Toshiyuki Sakai and his research team from the Department of Information Science at Kyoto University staged the attraction Computer Magnifying Glass, also known as Computer Physiognomy. Over sixty-four million people or some 350,000 per day visited the Osaka Expo ‘70. And for the first time in history, hundreds, if not thousands of people had their faces detected, extracted, and classified in this new state-of-the-art manner. With Computer Physiognomy, the general public sat in front of a technological system for computer vision and machine learning as their picture was taken by a television camera, then digitized, fed into a computer, and analyzed using a facial recognition algorithm based on Sakai’s technique. First, the system detected their face in this digital image of the face within its environment, by localizing any region in the picture with this type of object. Second, it extracted the relevant or selected facial features from this image data, including landmarks or points such as the eye, mouth, and nose corners, based on the patterns of their lines, which required the normalization of the image. And third, the system classified these faces by matching query images taken with a camera to template images stored in a database, comparing the faces of visitors to those of seven celebrity types.
Enlarge

Of course, Computer Physiognomy was not an artwork per se. At least, neither Toshiyuki Sakai nor the Exposition organizers ever wrote about the technological installation as art. Historically, world fairs did not ‘solicit the public’s suggestions about emerging devices, systems, or role definitions’, as political philosopher Langdon Winner points out. Rather, they staged closed, corporate-sponsored research and development of which ordinary people need only be in awe. And as visitors ‘strolled through the fair, they learned how to orient themselves to changes in living that seemed to have their own undeniable trajectory’. Combining the amusement park and technology museum, at world fairs ‘an almost visceral pleasure was being used to sell the comparatively cold, abstract, and at times unappealing accomplishments of the technological’. That is, the exhibition design for Computer Physiognomy at the Osaka Expo ’70 offered visitors a speculative futurism in which recognition technology was an already-accomplished fact; the future is now!
Thus, already in 1970 people were having the language of their faces read by a machine and translated into the text of some code. And much like at today’s media art exhibitions and festivals, the experience would have most likely impressed upon these visitors what Patricia de Vries and Willem Schinkel call a sense of ‘algorithmic anxiety’. Revolving ‘around the position of the self’ that is ‘socio-technically entangled’ with facial recognition technology, such an anxiety concerns ‘the very question in relation to whom or what subjects constitute themselves’, with visitors becoming aware of their own subjectivity as being one among other normativities, whether actual or potential, constrained or limitless. It would be another forty years before the first works of biometric art that use facial recognition as well as emotion recognition began to enter the discourse. Even so, Computer Physiognomy set the stage for the design of the biometric art that was to come.
Teaching Machines How to See the Face
While ‘the attraction itself was very successful’ at the World Exposition 1970, as Japanese-born computer scientist Takeo Kanade found, ‘the program was not very reliable’ in Computer Physiognomy. At the time, Kanade was doing his doctoral dissertation at Kyoto University, supervised by Toshiyuki Sakai, designer of the facial recognition algorithm used in Computer Physiognomy. Now, Kanade is one of the leading researchers in the field of facial recognition, affiliated with The Robotics Institute at Carnegie Mellon University in Pittsburgh, Pennsylvania. As Kanade detailed in his dissertation, for Computer Physiognomy the absence of success was not evidence of failure because the exhibit had a more direct use value for the futures of recognition technology. The pictures of visitor’s faces taken at the Sumitomo Pavilion during the Osaka Expo ’70 all had been ‘stored on ten magnetic tapes’, yielding a large dataset of 688 digital images for basic research. These images showed ‘young and old, males and females, with glass and hats, and faces with a turn, tilt, or inclination to a slight degree’. Using this face image dataset, Kanade tested the limitations as well as the performance of the computer program that he developed for his doctorate, and established the fundamental problem that for the last half century has challenged research and development in facial recognition technology: how can we teach a machine what the human face is and ways to see it?
Machine vision systems, like the human vision system itself, must learn how to see in an image what information is the face and what is not. After all, at this moment in the technological evolution of our human species, a machine cannot learn to see faces like a human (simulation), a human cannot see more with a machine (prosthetic), and a machine and a human can see differently together (augmentation), unless a human first teaches a machine what the face is in the first place.
However, machines have a difficult time seeing faces for a number of reasons, including: great variability in head rotation and tilt; obstruction of forms whether in whole or in part; relative brightness, contrast, and luminosity; and the three-dimensionality of the face as an object or shape as well as the four-dimensionality of facial behavior (three dimensions of space and one of time). Also, facial recognition does not work directly on the living face, but on re-presented or re-mediated faces, whether digital image or digitized copy. During the process of facial recognition, these face images must be corrected so that the face can be discriminated in relation to its environment. That is, the image must be normalized. And this normalization may include the compression of data from the image size and flattening of space from the visual field, which may severely constrain how a computer can recognize the object that is the face. Today, manifold approaches in technology have been advanced and may be applied in order to achieve such recognition. The degree of accuracy for any one approach over another depends largely upon the number of sample face images used to train the artificial intelligence, the features of these images, and the complexity of the classifier. Therefore, from the viewpoint of computer science, the face recognition done by a biometric artwork is a type of object or pattern recognition.
Yesterday’s Computer Physiognomy and today’s biometric art share a basic design by which an artificial intelligence, through computer vision and machine learning, performs facial recognition. In other words, these works hold in common an ideal structure wherein the arrangement and relation between parts is most suited to the purpose. This includes, especially: German media artist Julius von Bismarck, German digital designer Benjamin Maus and Austrian filmmaker Richard Wilhelmer’s Public Face in 2007; Taiwanese media artists He-Lin Luo, Jin-Yao Lin and Yi-Ping Hung’s Smiling Buddha in 2008; Marnix de Nijs’ series of biometric artworks from 2008 to 2011; as well as Uruguayan media artist Tomás Laurenzo, Chinese media artists Li-Yi Wei and Qin Cai’s Walrus in 2011; among others. Albeit, as de Nijs once confided to me, media artists are not necessarily aware of the correspondence between their contemporary biometric art and historical recognition technology.
In order for biometric art that uses facial recognition to become possible, several economic, political and social factors all had to click into place. From the outset of recognition technology in the mid-twentieth century, it has been part of the fields of computer, machine, and robotic vision, which are all branches of artificial intelligence. However, the innovation processes and outcomes behind recognition technology did not take place in a vacuum. Rather, these specialized problems in computer science also involved a cultural and social construction.
By the mid-to-late 1960s and early 1970s, as Kanade reviewed the literature for his dissertation, landmark researches began to take place on the machine recognition of the human face, such as those by Woody Bledsoe at Panoramic Research Inc. in Palo Alto, California, Toshiyuki Sakai at Kyoto University, and M.D. Kelly at Stanford University, among others. Such early efforts in recognition technology during the post-Sputnik Cold War period received an immense amount of financial support from military organizations. In the United States, for example, a lot of this funding originated with the Department of Defense (DOD), and its Advanced Research Projects Agency (ARPA), known today as the Defense Advanced Research Projects Agency (DARPA). Given a mission ‘to make pivotal investments in breakthrough technologies for national security’, this was the very same organization which underwrote the precursor to the Internet, ARPANET, as well as psychologist Paul Ekman’s first studies on cross-cultural facial behavior and universal emotion phenomenon. Consequent to this source of funding, much, but not all, early research and development in recognition technology was being done to fulfill the needs of the military. And the applications being anticipated encompassed the logistics of military perception, such as the identification of enemy combatants and terror suspects.
In the 1990s, as contextualized and historicized by Kelly Gates, a scholar in communication and science studies, the effort to teach machines how to see the face began to find prospective social utility and market value ‘in the surveillance and security priorities that underpinned neoliberal strategies of government’. Military organizations in the United States decided that it was time to evaluate the fruits of their federally-financed labors. And in 1993, the US Defense Department’s Counterdrug Technology Development Program, organized the Face Recognition Technology (FERET) program. The purpose of FERET was ‘to develop automatic face recognition capabilities that could be employed to assist security, intelligence, and law enforcement personnel in the performance of their duties’ by sponsoring research, collecting databases, and performing evaluations. This program lent an air of legitimacy to the whole endeavor of teaching machines what faces are and how to see them, convincing stakeholders, and encouraging developers.
By the mid-90s, prototypes for facial recognition began to emerge beyond the computer science laboratory. With the boom in information and communications technology, scientists at universities made themselves into entrepreneurs, hoping to capitalize on the needs of businesses and other organizations. Experiments with real-world applications started to take shape. And between 1994 and 1996, the first recognition technology companies began vying for capital and customers. These new commercially available systems had considerable limitations. But the game to invent and innovate facial recognition technology was on.
Then on September 11, 2001 four coordinated attacks by the terrorist group Al-Qaeda killed almost three thousand people in the United States. After this, research and development in facial recognition turned from a still-nascent effort to a large-scale endeavor, with a significant increase in government spending on research in both the public and private sectors. The Facial Recognition Vendor Test (FRVT), begun in 2000 at the National Institute of Standards and Technology (NIST) as the next stage of the FERET program, became an ongoing series of challenges in which corporations push the limits of the state-of-the-art, one that continues to this day. And by the mid-to-late 2000s, technology companies were innovating recognition technology using artificial intelligence, such as deep learning and neural networks, trained on face image datasets but applicable to new image datasets. Because of this, recognition technology could now be released for public consumption in the form of a commercial product, either open source or black box, such as an Application Programming Interface (API) or Software Development Kit (SDK). That is, around 2007, facial recognition became available to artists. And biometric art based on facial recognition began.
Challenging Our Face Consciousness
Biometric art that uses facial recognition is neither an art genre nor an artistic movement (-ism). Neither is it a place of study nor a school of thought. Rather, such biometric art is a contemporary art form in which an artist experiments with the way recognition technology works as an instrument or tool for artistic creation. It is a critical practice with specificity and value which provokes de-automizations and re-negotiations with other human practices, such as facial recognition. Through its dynamic intersections with these face studies and recognition technology, biometric art in turn is constitutively entangled with the interpretive processes of a meta-critical reflection. Across highly diverse artworks, some biometric art plays with facial recognition technology, some subverts; some celebrates the accomplishment, some critiques the arrogance; some puts facial recognition on stage, some on trial.
As such, the various critical practices for facial-recognition-based biometric art may be considered not only an intellectual but also an ethical activity. These practices afford for the conceptual models by which people are classified, computed, and even controlled on the basis of face to be made, manipulated, talked about, and tested. Rupturing our everyday habitual and lived experience of the face, biometric art reveals the ways in which facial recognition technology and automated facial expression analysis may affect our dispositions, beliefs, and attitudes towards facial behavior, how we think about who we are, and the very nature of ‘face consciousness’.
Devon Schiller is a cultural semiotician and media historian born in Cambridge, Massachusetts and based in Vienna, Austria. His scholarship centres around facial expression of emotion and how methods of experiment inform its conceptualization. A recipient of a DOC Fellowship from the Austrian Academy of Sciences, Devon currently pursues his doctorate at the University of Vienna. He holds a master's degree in media art history from Danube University as well as a bachelor's in art history and studio painting from the Kansas City Art Institute. Devon has also trained in the Facial Action Coding System (FACS) at the University of California Berkeley, certified in the Neuropsychological Gesture Coding System (NEUROGES) at the German Sport University Cologne, and has conducted grant-supported research on facial recognition technology at the Fraunhofer Institute for Integrated Circuits.
References
Fedorova, Ksenia. Tactics of Interfacing: Encoding Affect in Art and Technology, Cambridge, MA: MIT Press, 2020.
Flusser, Vilém. Into the Universe of Technical Images, transl. by N.A. Roth, Minneapolis, MN: University of Minnesota Press, 2011.
Gates, Kelly A. Our Biometric Future: Facial Recognition Technology and the Culture of Surveillance, New York: New York University Press, 2011.
Nake, Frieder. ‘Surface, Interface, Subface: Three Cases of Interaction and One Concept’, in: Paradoxes of Interactivity: Perspectives for Media Theory, Human-Computer Interaction, and Artistic Investigations, ed. by U. Seifert, J. Hyun Kim, and A. Moore, Bielefeld: Transcript, 2008, pp. 92-109, DOI: 10.25969/mediarep/2719.
Rajewsky, Irina O. ‘Intermediality, Intertextuality, and Remediation: A Literary Perspective on Intermediality’, Intermédialités 2005, no. 6, pp. 43-64, DOI: 10.7202/1005505ar.
Schuller, Björn W. ‘Multimodal Affect Databases: Collection, Challenges, and Chances’, in: The Oxford Handbook of Affective Computing, ed. by R.A. Calvo, S.K. D’Mello, J. Gratch, and A. Kappas, New York: Oxford University Press, 2015, pp. 232-233.
Vries, Patricia de and Willem Schinkel. ‘Algorithmic Anxiety: Masks and Camouflage in Artistic Imaginaries of Facial Recognition Algorithms’, Big Data & Society 2019, vol. 6, no. 1, pp. 1-12, DOI: 10.1177/2053951719851532.
Winner, Langdon. ‘Who Will We Be in Cyberspace?’ The Information Society 12, no. 1: 630-72 (1996). DOI: 10.1080/019722496129701.